【2025年最新】ベクトルDBおすすめ9選!失敗しない選び方を専門家が5つのポイントで徹底解説

目次
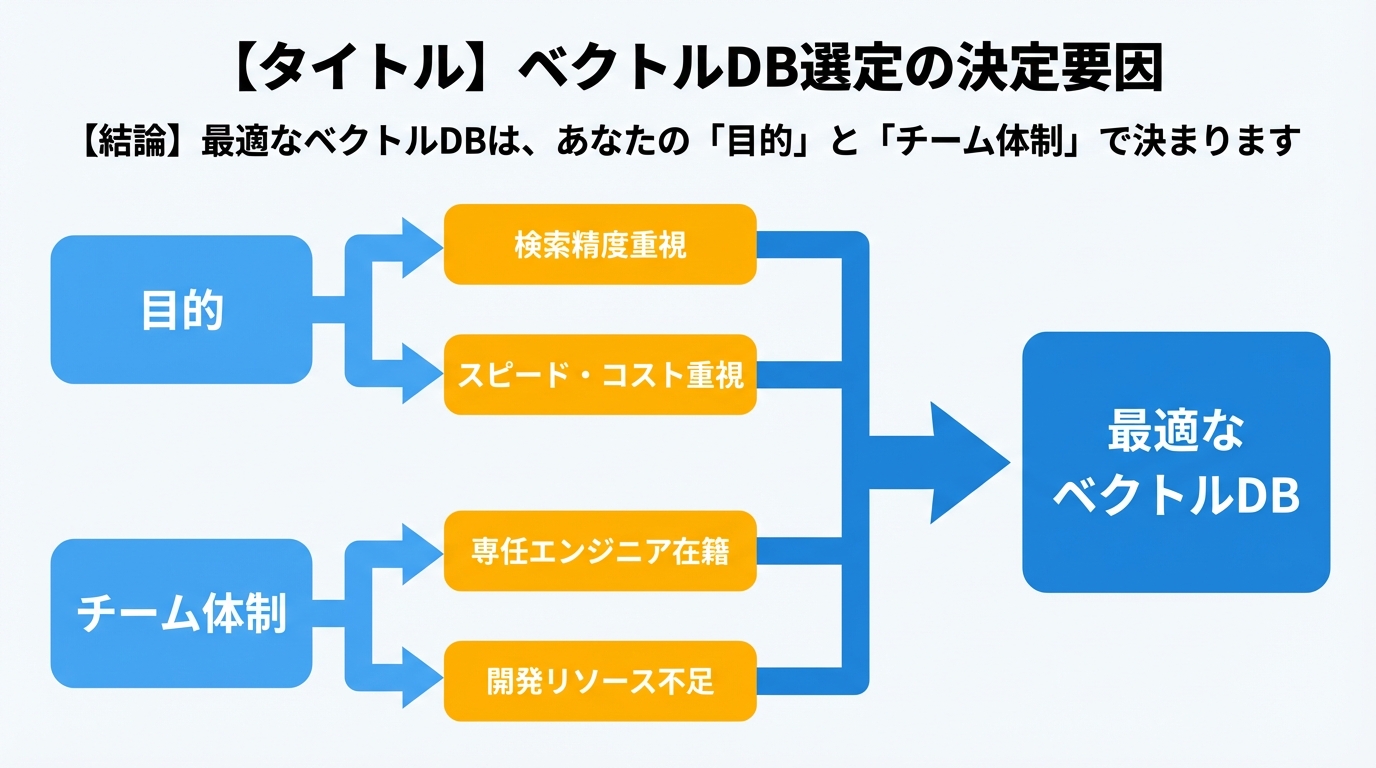
【結論】最適なベクトルDBは、あなたの「目的」と「チーム体制」で決まります
【結論】最適なベクトルDBは、あなたの「目的」と「チーム体制」で決まりますの図解
「どのベクトルDBが一番良いんだろう…?」そんな悩みを抱えていませんか?
「生成AIで新しいアプリケーションを作りたい!」 「社内の情報をAIで検索できるようにして、業務を効率化したい!」
そんな思いで情報収集を始めたものの、**「ベクトルデータベース」**という聞き慣れない言葉の壁にぶつかっていませんか?
- Pinecone, Chroma, pgvector... たくさんありすぎて、どれが自分に合っているのか分からない。
- 「マネージド」と「セルフホスト」って何が違うの?
- 技術的な記事は難しすぎて、結局どうすればいいのか判断できない。
- 技術選定で失敗して、時間もコストも無駄にしたくない…。
もしあなたが今、こんな状況にあるのなら、この記事はきっとお役に立てるはずです。この記事では、単におすすめのサービスを羅列するだけではありません。あなたのプロジェクトを成功に導くために、「何を」「どのように」選べばよいのか、その判断軸を誰にでも分かるように、そして徹底的に詳しく解説していきます。
結論ファースト:あなたの状況に合わせた最適解の見つけ方
時間がない方のために、この記事の結論からお伝えします。
あなたに最適なベクトルデータベースは、ただ一つに決まるものではありません。それは、「何を実現したいか(目的)」と「誰が作るのか(チーム体制)」という2つの軸によって決まります。
- とにかく早く、リスクを抑えて始めたいなら→マネージドサービス(例: Pinecone, Weaviate)が有力な選択肢です。専門家が管理する既製品の安心感があります。
- コストを抑え、将来的な拡張性や柔軟性を重視するなら→自社構築/PaaS(例: pgvector, Supabase)が向いています。自分たちでコントロールできる自由度が魅力です。
この記事を最後まで読めば、あなたは自信を持って、ご自身のプロジェクトに最適なベクトルデータベースを選択できるようになるでしょう。それでは、一緒にベクトルデータベースの世界を探求していきましょう。
H2: そもそもベクトルデータベースとは?なぜ今、注目されているの?
H2: そもそもベクトルデータベースとは?なぜ今、注目されているの?の図解
まず最初のステップとして、「ベクトルデータベースとは何か」を簡単におさらいしましょう。ここを理解すると、なぜ多くの選択肢があるのか、そして選び方のポイントがスッと頭に入ってきます。
H3: 生成AI・RAG時代に必須の「記憶装置」
ベクトルデータベースは、一言でいうと**「AIのための新しい記憶装置」**です。
ChatGPTのような大規模言語モデル(LLM)は非常に賢いですが、学習データに含まれていない最新の情報や、社内の機密情報のようなプライベートなことは知りません。そこで、AIに外部の知識を与える**「RAG(検索拡張生成)」**という技術が注目されています。
RAGは、ユーザーから質問が来たときに、関連する情報をデータベースから探し出し、その情報をヒントとしてAIに渡すことで、より正確でリッチな回答を生成させる仕組みです。この**「関連する情報を探し出す」**部分で大活躍するのが、ベクトルデータベースなのです。
近年のAI技術の急速な普及は、市場データにも表れています。専門家の分析によると、ベクトルデータベースの市場は今後も力強く成長していくと予測されており、これは多くの企業がAI活用に本腰を入れ始めた証拠と言えるでしょう。情報処理推進機構(IPA)が発行する「AI白書」などでも、こうした技術トレンドが詳細に報告されています。 (出典:情報処理推進機構(IPA)「AI白書」)
H3: 従来のデータベースとの決定的違いは「意味」で検索できること
では、なぜ従来のデータベースではダメなのでしょうか?
従来のデータベース(Excelや一般的な顧客管理システムを想像してください)は、**「キーワードが完全に一致するかどうか」**で情報を探します。例えば、「AI 活用」で検索すれば、その文字列が含まれる文書は見つかりますが、「人工知能のビジネス利用」という文書は、意味が似ていてもヒットしません。
一方、ベクトルデータベースは、言葉や画像、音声などを「ベクトル」と呼ばれる数値の羅列に変換して保存します。このベクトルは、データの「意味」や「文脈」を捉えています。そのため、「AI 活用」と「人工知能のビジネス利用」のように、表現は違っても意味が近いものを「似ている」と判断して探し出すことができるのです。
この**「あいまい検索」や「意味での検索」**こそが、ベクトルデータベースの最も重要な特徴です。
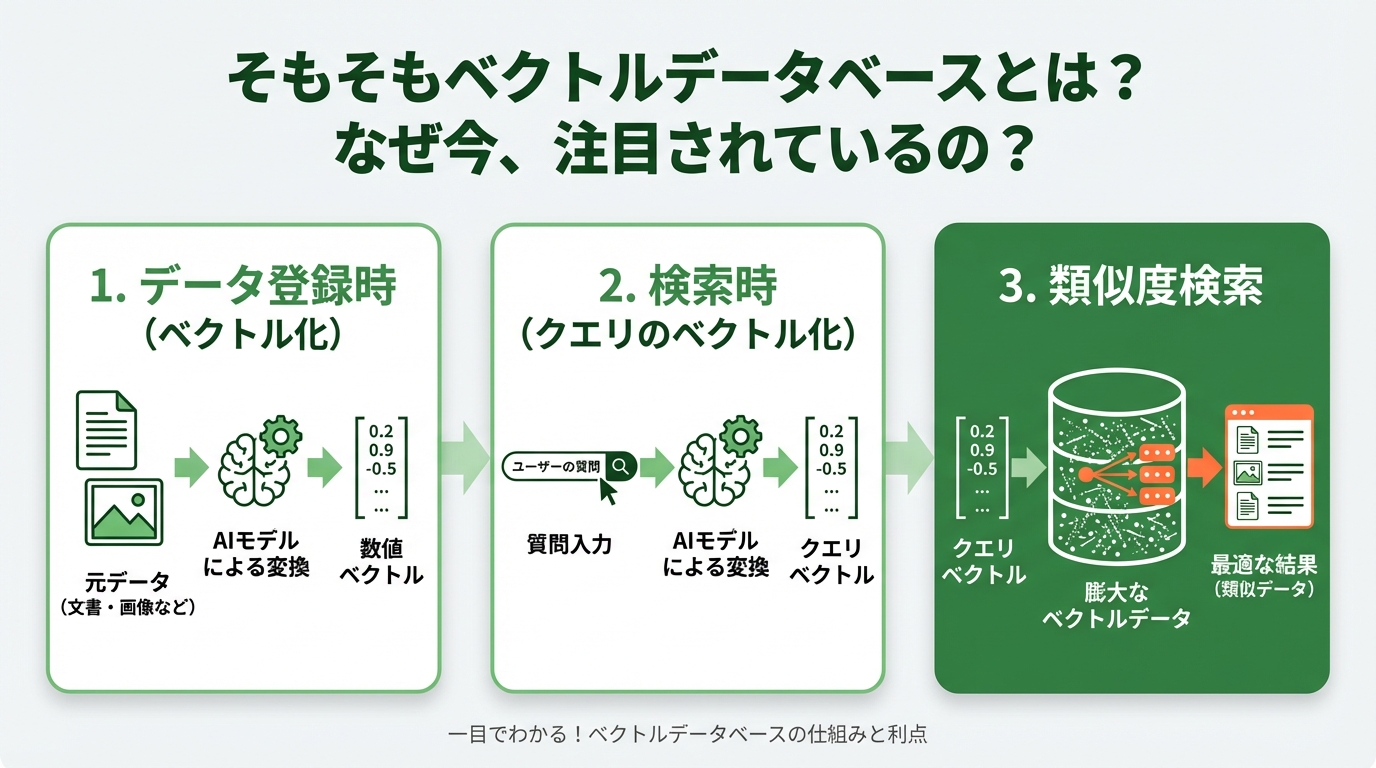
H3: [図解] ベクトル検索の仕組みを3ステップで簡単解説
「ベクトル」や「意味で検索」と言われても、まだピンとこないかもしれませんね。仕組みは意外とシンプルです。
[ここに「ベクトル検索の仕組み」の図解を挿入]
- キャプション:
- データ登録時(ベクトル化):文書や画像などの元データを、OpenAIなどのAIモデル(Embedding Model)を使って「ベクトル(数値の羅列)」に変換し、ベクトルDBに保存します。
- 検索時(クエリのベクトル化):ユーザーが入力した質問(クエリ)も、同じAIモデルを使ってベクトルに変換します。
- 類似度検索:データベースに保存されている膨大なベクトルの中から、質問のベクトルと「距離」が最も近い(=最も似ている)ものを高速で探し出し、結果として返します。
この3ステップによって、AIは文脈に合った適切な情報を手に入れることができるのです。
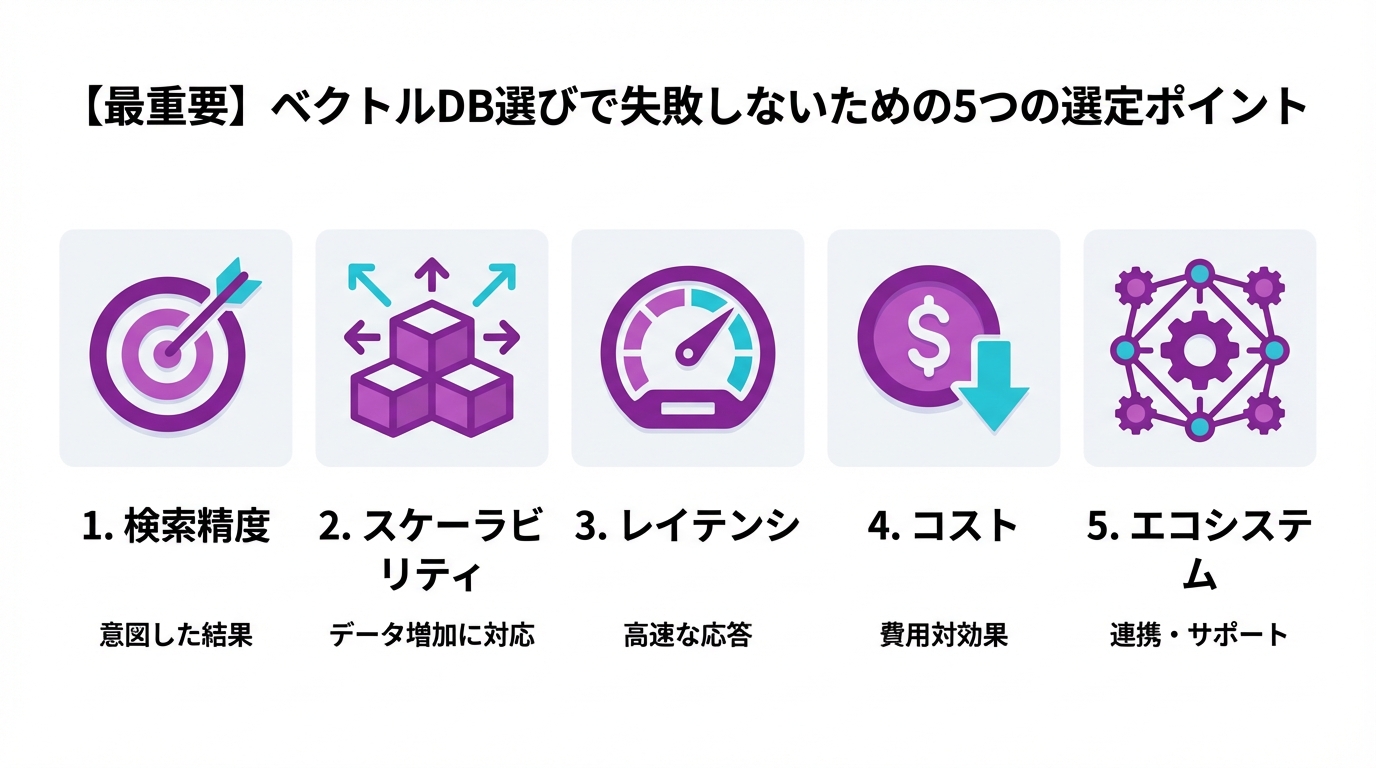
H2: 【最重要】ベクトルDB選びで失敗しないための5つの選定ポイント
H2: 【最重要】ベクトルDB選びで失敗しないための5つの選定ポイントの図解
さて、基本的な仕組みがわかったところで、いよいよ本題の「選び方」です。世の中には多くのベクトルDBがありますが、以下の5つのポイントに沿って考えれば、選択肢は自然と絞られてきます。
H3: Point 1: 目的は何か?(RAGチャットボット、推薦エンジン、画像検索…)
まず最初に考えるべきは、「ベクトルDBを使って何を実現したいのか?」という目的です。目的によって、求められる機能や性能が大きく変わってきます。
- 社内文書検索・RAGチャットボット:
- 重視すること:検索精度、キーワード検索とベクトル検索のハイブリッド機能、アクセス権限管理。
- 解説:主にテキストデータを扱います。単純な類似検索だけでなく、「〇〇という単語が含まれ、かつ△△という意味に近い文書」といった複合的な検索ができると便利です。
- ECサイトの推薦エンジン:
- 重視すること:大量のデータ処理能力、リアルタイムでの更新、多様なフィルター機能。
- 解説:ユーザーの行動履歴(閲覧、購入など)をリアルタイムでベクトル化し、関連商品を推薦します。「価格が5,000円以下で、青色で、スポーティなデザインのTシャツ」のような複雑な条件(メタデータフィルタリング)に対応できるかが重要になります。
- 画像・動画検索システム:
- 重視すること:大容量の非構造化データの扱いや処理速度。
- 解説:テキストに比べてデータサイズが大きくなるため、ストレージ効率やインデックス作成の速度がパフォーマンスに影響します。
まずはあなたのプロジェクトがどのタイプに当てはまるか、そしてどんな機能が必須になるかを洗い出してみましょう。
H3: Point 2: チームの技術力は?(「購入」か「自社構築」かの分かれ道)
次に問われるのが、あなたのチームの体制とスキルセットです。これは、後述する**「マネージドサービス(購入)」と「自社構築(構築)」**のどちらを選ぶかという、最も大きな分岐点になります。
- 専任のインフラエンジニアやDB専門家がいない場合:
- データベースのセットアップ、チューニング、バックアップ、セキュリティ対策などを自前で行うのは非常に困難です。この場合は、専門家がすべて管理してくれるマネージドサービスを選ぶのが賢明でしょう。
- PostgreSQLなどのデータベース運用経験が豊富なエンジニアがいる場合:
- 既存の知識を活かせる自社構築/PaaS(Platform as a Service)が視野に入ります。特に、
pgvectorのように使い慣れたPostgreSQLを拡張するタイプのものは、学習コストを抑えつつ導入できる可能性があります。
- 既存の知識を活かせる自社構築/PaaS(Platform as a Service)が視野に入ります。特に、
- AI/MLエンジニアはいるが、インフラは詳しくない場合:
- この場合も、まずはマネージドサービスから始めるのが安全です。AIモデルのチューニングなどに集中でき、インフラの悩みから解放されます。
チームの能力を正直に見極めることが、プロジェクト成功の鍵を握ります。
H3: Point 3: データ規模と性能要件は?(応答速度はどれくらい必要?)
あなたのアプリケーションは、どれくらいのデータ量を扱い、どれくらいの速さで応答する必要があるでしょうか?
- データ規模(ベクトル数):
- 最初は数千〜数万件でも、将来的に数百万、数千万、あるいは億単位にまで増える可能性はありますか?DBによっては、大規模データになると性能が劣化したり、コストが急増したりするものがあります。将来的なスケールを見越した選択が重要です。
- 性能要件(QPSとレイテンシ):
- QPS (Queries Per Second):1秒あたりに処理できる検索リクエストの数です。多くのユーザーが同時に利用するサービスでは、高いQPSが求められます。
- レイテンシ:検索リクエストを送ってから結果が返ってくるまでの時間です。リアルタイム性が求められるチャットボットや推薦エンジンでは、低レイテンシ(速い応答)が不可欠です。
プロトタイピング段階ではそこまで気にする必要はないかもしれませんが、本番運用を見据えるなら、各サービスが公開しているベンチマークなどを参考に、性能要件を満たせるか確認しましょう。
H3: Point 4: コストはどれくらいかけられる?(初期費用 vs 運用費用)
コストの考え方も、アプローチによって大きく異なります。
- マネージドサービスの場合:
- 多くは**月額のサブスクリプションモデル(運用費用, OpEx)**です。データ量やリクエスト数に応じた従量課金が一般的で、コストが予測しやすい反面、利用量が増えると高額になる可能性があります。
- 自社構築の場合:
- データベースを動かすためのサーバー代(クラウド利用料)が主な運用費用になります。初期の構築コストはかかりますが、最適化すればランニングコストを低く抑えられる可能性があります。
- インテグレーションサービスの場合:
- 専門企業に開発を依頼するモデルです。この場合は、**初期開発費用(資本的支出, CapEx)**がメインとなり、その後の運用・保守費用は別途契約となることが多いです。予算の立て方が根本的に異なります。
単純な月額料金だけでなく、データ転送料金やAIモデルのAPI利用料など、全体の**総所有コスト(TCO)**で比較検討することが重要です。
H3: Point 5: セキュリティとデータガバナンスは?(公的機関の指針に学ぶ)
特に企業で利用する場合、セキュリティは絶対に無視できない要素です。個人情報や機密情報を扱うなら、なおさらです。
- データの保管場所:データはどこ(国・地域)のデータセンターに保存されますか?
- 暗号化:通信経路や保存データは暗号化されていますか?
- アクセス制御:誰がどのデータにアクセスできるかを細かく制御できますか?(行レベルセキュリティなど)
- コンプライアンス:GDPRやCCPAなど、各国のプライバシー規制に対応していますか?
どのようなクラウドサービスを利用するにせよ、その選定においては信頼性が重要です。例えば、日本のデジタル庁は「政府情報システムにおけるクラウドサービスの利用に係る基本方針」の中で、政府が利用するクラウドサービスに求めるセキュリティ要件などを定めています。こうした公的な指針は、民間企業がサービスを選ぶ上でも非常に参考になります。自社のセキュリティポリシーと照らし合わせ、要件を満たすサービスを選定しましょう。 (出典:デジタル庁「政府情報システムにおけるクラウドサービスの利用に係る基本方針」)
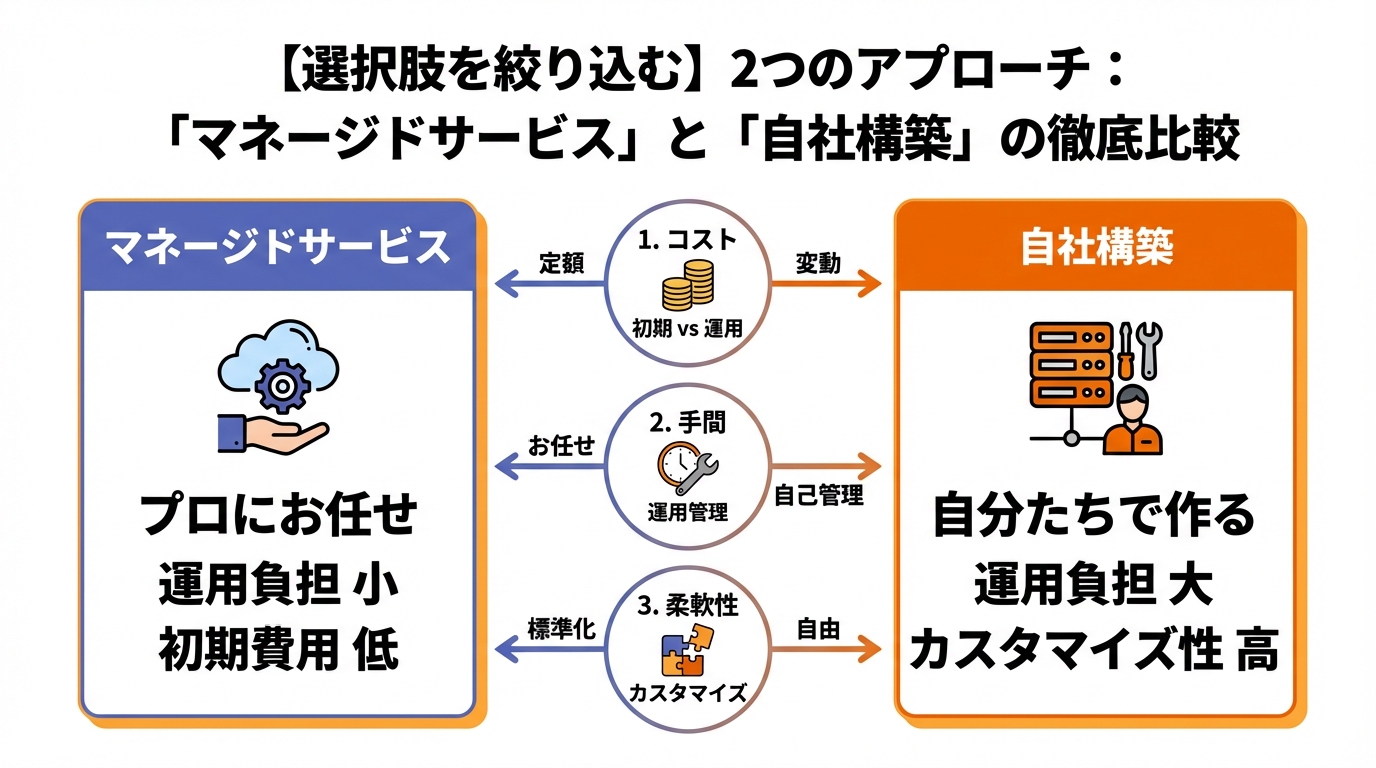
H2: 【選択肢を絞り込む】2つのアプローチ:「マネージドサービス」と「自社構築」の徹底比較
H2: 【選択肢を絞り込む】2つのアプローチ:「マネージドサービス」と「自社構築」の徹底比較の図解
5つの選定ポイントが見えてきたところで、具体的なアプローチの選択に入りましょう。ベクトルDBの世界は、大きく分けて「マネージドサービス」と「自社構築」の2つの道があります。これは、例えるなら「レストランで食事をするか(マネージド)」、「キッチン付きの物件を借りて自分で料理をするか(自社構築)」の違いに似ています。
H3: アプローチ1:マネージドサービス(購入)- とにかく早く始めたいチーム向け
これは、ベクトルデータベースを専門とする企業が、インフラの構築から運用、保守までをすべて引き受けてくれるサービスです。ユーザーはAPIを呼び出すだけで、すぐにベクトル検索機能を利用できます。
H4: メリット:専門知識不要、すぐに使える、運用を任せられる
- 市場投入までの時間短縮:サーバーのセットアップやソフトウェアのインストールが不要なため、アイデアをすぐに形にできます。
- 運用負荷の軽減:パフォーマンスのチューニング、バックアップ、障害対応などをすべてサービス提供側に任せられます。開発チームはアプリケーション開発に集中できます。
- 高度な機能:専門企業が開発しているため、スケーラビリティやセキュリティ、高度なフィルタリング機能などが最初から高いレベルで提供されていることが多いです。
H4: デメリット:コスト高、柔軟性が低い、ベンダーロックインのリスク
- コスト:利便性が高い分、自社で構築するよりも一般的にコストは高くなる傾向があります。データ量や利用量が増えると、費用が想定以上にかさむ可能性もあります。
- 柔軟性の低さ:提供されている機能の範囲内でしか開発できません。特殊なカスタマイズや、データベース内部の細かいチューニングは困難です。
- ベンダーロックイン:特定のサービスに深く依存してしまうと、将来的に他のサービスへ乗り換える際の移行コストが非常に高くなるリスクがあります。
H4: こんなチームにおすすめ
- 専任のインフラエンジニアがいないスタートアップや事業部
- 何よりも開発スピードを優先し、早く市場に製品を投入したいチーム
- コアビジネスがAIではなく、AI機能をあくまで一部として利用したい企業
H3: アプローチ2:自社構築/PaaS(構築)- 柔軟性とコストを重視するチーム向け
これは、pgvectorやMilvusといったオープンソースのソフトウェアを自分たちでサーバーにインストールして運用するか、Supabaseのようにデータベース機能を提供するPaaS上で利用するアプローチです。
H4: メリット:高いカスタマイズ性、低コスト、技術的知見が貯まる
- 完全なコントロール:データベースの構成やチューニング、周辺ツールとの連携など、すべてを自分たちの思い通りに設計できます。
- コスト効率:最適化すれば、マネージドサービスよりも運用コストを大幅に抑えられる可能性があります。オープンソースソフトウェア自体は無料です。
- ベンダーロックインの回避:オープンソースベースであるため、特定の企業に依存することがありません。クラウドプロバイダーの乗り換えなども比較的容易です。
- データ統合:既存のアプリケーションデータベース(例: PostgreSQL)にベクトル検索機能を追加する場合、データを一元管理でき、運用がシンプルになります。
H4: デメリット:導入・運用に専門知識と工数がかかる、自己責任
- 高い技術的ハードル:データベースの設計、構築、パフォーマンスチューニング、セキュリティ対策、バックアップ、障害対応など、すべてを自社で行うための専門知識とスキルが必要です。
- 導入・運用工数:アプリケーション開発以外のインフラ管理に多くの時間とリソースを割く必要があります。
- 自己責任:何か問題が発生した場合、自分たちで原因を調査し、解決しなければなりません。
H4: こんなチームにおすすめ
- PostgreSQLなどのデータベース運用経験が豊富なエンジニアがいるチーム
- 長期的なコスト管理を重視し、内製化によるコストメリットを追求したい企業
- 独自の要件が多く、細かいカスタマイズが必須となるプロジェクト
H2: 【2025年版】主要ベクトルデータベース徹底比較!おすすめ9選
さて、2つのアプローチの違いが明確になったところで、いよいよ具体的なサービスを見ていきましょう。ここでは、現在主流となっている9つのベクトルデータベースを「マネージド型」と「自社構築/PaaS型」に分けてご紹介します。
H3: [比較表] 主要ベクトルDB9選 - 特徴・料金・最適なユースケースが一目でわかる
[ここに主要ベクトルDB9選の比較表を挿入]
| サービス名 | タイプ | 特徴 | 料金目安(Free Tier) | 最適なユースケース |
|---|---|---|---|---|
| Pinecone | マネージド | 高速・高精度。大規模向け。開発者体験が良い。 | あり(1Pod, 768次元で約500万ベクトルまで) | 本番環境での大規模RAG、推薦システム |
| Weaviate | マネージド/OSS | ハイブリッド検索、GraphQL対応。マルチモーダル。 | あり(100万オブジェクトまで) | 複雑な検索要件、画像・テキスト複合検索 |
| Qdrant Cloud | マネージド/OSS | Rust製で高速。フィルタリング機能が強力。 | あり(1GBストレージ, 1Mベクトルまで) | 高度なフィルタリングが必要な推薦・検索 |
| Chroma (Hosted) | マネージド/OSS | シンプルで始めやすい。LangChainとの親和性が高い。 | なし(OSS版は無料) | プロトタイピング、小〜中規模アプリ |
| pgvector | 拡張機能/OSS | PostgreSQL内で完結。信頼性とデータ統合が強み。 | 利用するPaaS/クラウドによる(Supabase等で無料枠あり) | 既存PostgreSQLユーザー、データ一元管理 |
| Redis | インメモリDB/OSS | 高速。ベクトル検索は機能の一部として提供。 | 利用するクラウドによる(無料枠あり) | リアルタイム性が最重要視されるアプリ |
| Elasticsearch | 検索エンジン/OSS | 全文検索の巨人がベクトル検索に対応。実績豊富。 | 利用するクラウドによる(無料枠あり) | 既存Elasticsearchユーザー、全文検索との併用 |
| Milvus | 特化型DB/OSS | 大規模・高性能向けに設計されたOSS。 | セルフホストのためサーバー代のみ | 大規模な画像検索、学術研究 |
| Chroma (Self-hosted) | 特化型DB/OSS | シンプルで導入が容易なOSS。 | サーバー代のみ | RAGアプリのローカル開発、PoC |
H3: マネージド型DBの代表格 - 手厚いサポートですぐに始めたいなら
H4: 1. Pinecone
ベクトルデータベースのパイオニア的存在。高いパフォーマンスとスケーラビリティ、そして優れた開発者体験で多くの企業に採用されています。本番環境での大規模アプリケーションを構築する際の第一候補となるでしょう。
- 長所:非常に高速な検索、大規模データへの対応力、使いやすいAPI。
- 短所:他のサービスと比較してコストが高くなる可能性がある。
- おすすめな人:性能と信頼性を最優先する本番プロジェクトを抱える開発者。
H4: 2. Weaviate
オープンソース発のベクトルデータベースで、マネージドサービスも提供。キーワード検索とベクトル検索を組み合わせた「ハイブリッド検索」や、テキストと画像を同時に扱えるマルチモーダル機能が強力です。
- 長所:柔軟な検索機能、GraphQL APIのサポート、オープンソースであることの安心感。
- 短所:非常に大規模な用途ではPineconeに軍配が上がるケースも。
- おすすめな人:複雑な検索ロジックや、テキスト以外のデータも扱いたい開発者。
H4: 3. Qdrant Cloud
パフォーマンスとメモリ効率を重視してRustで書かれたベクトルデータベース。特に、検索結果を絞り込むための「メタデータフィルタリング」機能が非常に高速かつ強力で、多くの条件を組み合わせるユースケースで真価を発揮します。
- 長所:高速なフィルタリング、メモリ効率の良さ、豊富なクライアントライブラリ。
- 短所:比較的新しいサービスのため、コミュニティの規模はこれから。
- おすすめな人:ECサイトの推薦エンジンのように、多くの条件で検索結果を絞り込みたい開発者。
H4: 4. Chroma (Hosted)
※注: 2025年8月現在、公式のホステッド(マネージド)版は開発中ですが、多くのサードパーティが提供しています。ここではOSS版の思想を汲んだマネージドサービスを想定しています。 シンプルさと開発者体験を重視したオープンソースDB、Chromaのマネージド版です。LangChainなどのフレームワークとシームレスに連携でき、プロトタイピングを素早く行うのに最適です。
- 長所:とにかく簡単に始められる、主要なAIフレームワークとの連携がスムーズ。
- 短所:大規模な本番運用には機能や性能面で不安が残る可能性。
- おすすめな人:まずは手元で早くRAGアプリを試してみたい開発者や研究者。
H3: 既存DBの拡張機能/セルフホスト型 - 柔軟性と拡張性を求めるなら
H4: 5. pgvector (PostgreSQL)
最も注目されている選択肢の一つ。世界で最も普及しているオープンソースのリレーショナルデータベース「PostgreSQL」の拡張機能です。これにより、使い慣れたPostgreSQL上でベクトルデータを扱えるようになります。SupabaseなどのPaaSを利用すれば、インフラ管理の手間を大幅に削減できます。
- 長所:既存のPostgreSQL資産や知識を活かせる、リレーショナルデータとベクトルデータを一元管理できるため運用がシンプル、信頼性が高い。
- 短所:専用DBと比較すると、最高レベルの性能を出すにはチューニングの知識が必要。
- おすすめな人:すでにPostgreSQLを利用している、またはデータの一元管理を重視する開発者。
H4: 6. Redis
高速なインメモリデータベースとして有名なRedisも、ベクトル検索機能を提供しています。すべてのデータをメモリ上に保持するため、非常に高速な応答が可能です。
- 長所:圧倒的な低レイテンシ、既存のRedis知識を活かせる。
- 短所:メモリに乗り切らない大規模なデータセットには向かない、永続化の設計に注意が必要。
- おすすめな人:金融取引の不正検知など、リアルタイム性が何よりも重要なアプリケーションを開発する人。
H4: 7. Elasticsearch
全文検索エンジンとしてデファクトスタンダードの地位を確立しているElasticsearchも、強力なベクトル検索(kNN検索)機能を統合しています。
- 長所:全文検索とベクトル検索をシームレスに組み合わせられる、長年の実績と巨大なエコシステム。
- 短所:ベクトル検索専用DBと比べると、パフォーマンスや機能面で見劣りする可能性。
- おすすめな人:すでにElasticsearchを導入しており、既存の検索システムを拡張したいと考えている人。
H4: 8. Milvus
大規模なベクトル検索のためにゼロから設計された、高性能なオープンソースのベクトルデータベースです。非常に多くのインデックスタイプをサポートしており、様々なユースケースに合わせて最適な設定を選択できます。
- 長所:高いスケーラビリティとパフォーマンス、柔軟なインデックス設定。
- 短所:高機能な分、構築や運用の難易度は高い。
- おすすめな人:数億〜数十億規模のベクトルを扱う、非常に大規模な検索システムを構築する必要があるチーム。
H4: 9. Chroma (Self-hosted)
マネージド版でも紹介したChromaの、セルフホスト版です。pip install chromadbの一行でローカル環境にインストールでき、すぐに試せる手軽さが最大の魅力です。
- 長所:導入が非常に簡単、開発やPoC(概念実証)に最適。
- 短所:本番環境での大規模運用には向いていない。
- おすすめな人:ベクトルDBを初めて触る人、LangChainのチュートリアルを試したい学生や開発者。
<中盤の内部リンク挿入箇所>
関連記事:『ベクトルRAG開発 次世代知識検索システム URL: https://nands.tech/vector-rag』
H2: ユースケース別!あなたに最適なベクトルDBはこれだ【具体例で解説】
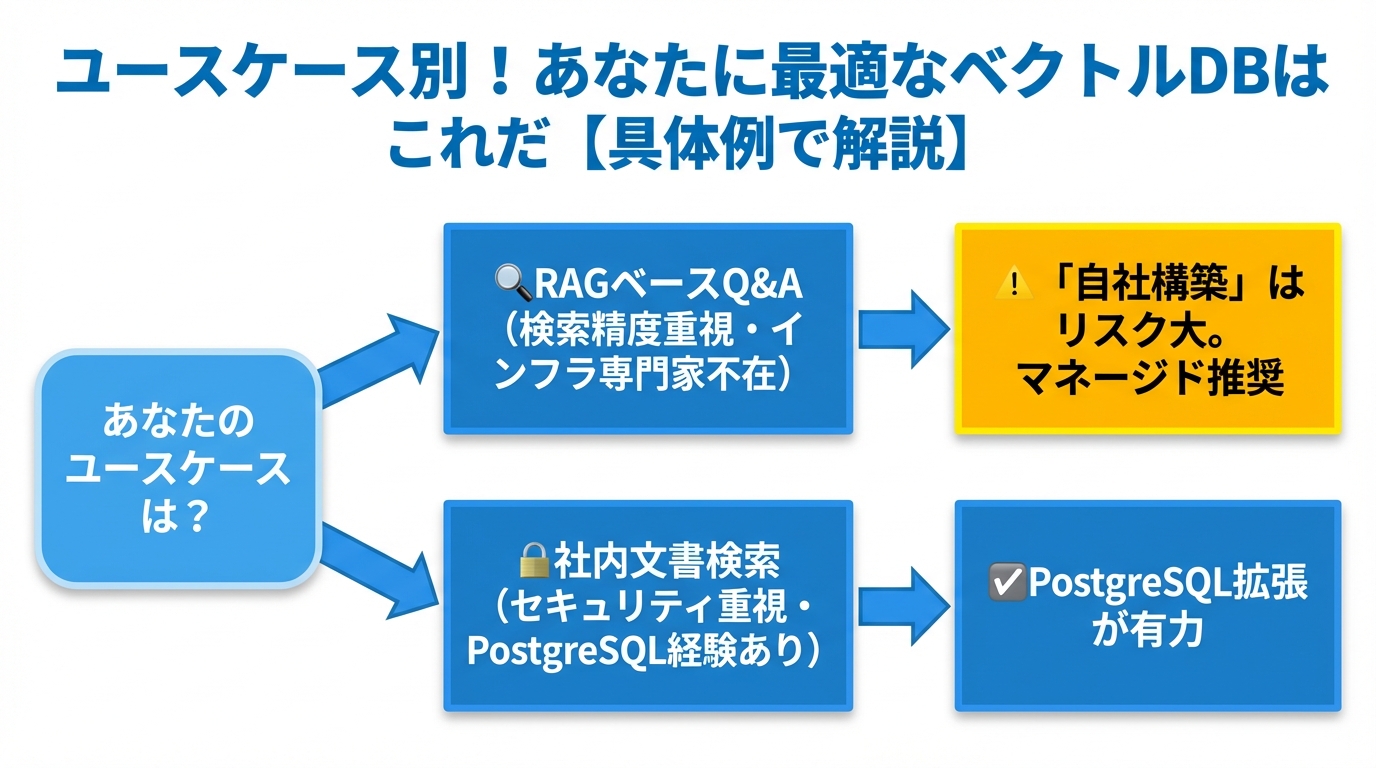
H2: ユースケース別!あなたに最適なベクトルDBはこれだ【具体例で解説】の図解
理論や比較だけでは、まだ自分ごととして捉えにくいかもしれません。ここでは、具体的な企業のシナリオを想定し、どのような思考プロセスでDBを選んでいくべきかを見ていきましょう。
H3: ケーススタディ1:スタートアップA社(東京都)「まずはMVPを素早く開発したい」
- 状況:5名の開発チーム。生成AIを活用した新しいQ&Aサービスを開発中。インフラ専任者はおらず、バックエンドエンジニアが兼務。とにかく早くMVP(Minimum Viable Product)をリリースして市場の反応を見たい。
- 思考プロセス:
- 目的:RAGベースのQ&Aサービス。検索精度は重要だが、まずは動くものを作ることが最優先。
- チーム体制:インフラの専門家がいない。開発リソースは限られている。
- 結論:「自社構築」はリスクが高い。インフラ管理に時間を取られ、本来のサービス開発が遅延する可能性がある。**「マネージド」**か、**インフラ管理が容易な「PaaS」**を選ぶべき。
- 具体的な選択肢:
- Supabase (with pgvector):バックエンド機能一式が揃っており、PostgreSQLの知識があればすぐに始められる。無料枠も充実しており、MVP開発には最適。データの一元管理も魅力。
- Chroma (Self-hosted/Hosted):
pipで簡単にインストールでき、ローカルでの開発が非常にスムーズ。LangChainとの連携も簡単で、素早いプロトタイピングに向いている。 - Pinecone:開発スピードをさらに上げたい、かつ初期からある程度の性能を担保したいなら有力。無料枠でMVPを開発し、スケールするなら有料プランへ移行する戦略。
H3: ケーススタディ2:中堅企業B社(大阪府)「社内ナレッジ検索システムを構築したい」
- 状況:従業員500名。情報システム部が運用を担当。社内に散在するマニュアルや議事録、規定集などを横断的に検索できるAIシステムを導入し、業務効率化を図りたい。既存の顧客データなどはPostgreSQLで管理している。
- 思考プロセス:
- 目的:社内文書検索。セキュリティとアクセス権管理が非常に重要。
- チーム体制:PostgreSQLの運用経験はあるが、AIやベクトルDBの専門家はいない。
- 結論:既存のデータ資産や運用ノウハウを活かすのが得策。全く新しい技術スタックを導入するより、**既存のPostgreSQLを拡張する
pgvector**が有力候補。ただし、自社でのRAGシステム構築に不安があるなら、専門家の支援も検討すべき。
- 具体的な選択肢:
- pgvector on AWS/GCP:既存のインフラ運用ノウハウを活かし、クラウド上にPostgreSQLを立てて
pgvectorを導入。データも既存DBと統合しやすく、ガバナンスを効かせやすい。 - マネージドDB (Pinecone, Weaviate 등):検索精度や高度な機能を求めるなら、マネージドDBも選択肢。ただし、既存DBとのデータ同期の仕組みを別途構築する必要がある。
- 開発支援サービス (インテグレーター):
nands.techのような専門企業に相談し、要件定義から構築までを依頼するアプローチ。技術的な不安を解消し、確実な導入が可能。
- pgvector on AWS/GCP:既存のインフラ運用ノウハウを活かし、クラウド上にPostgreSQLを立てて
H3: ケーススタディ3:大企業C社(愛知県)「大規模ECサイトの推薦エンジンを刷新したい」
- 状況:数百万人の会員と数千万点の商品を持つ大手ECサイト。データサイエンティストとインフラエンジニアからなる専任チームが存在。現在の推薦エンジンの性能に課題があり、ベクトル検索を活用した高度なパーソナライズを実現したい。
- 思考プロセス:
- 目的:大規模な推薦エンジン。低レイテンシ、高QPS、複雑なフィルタリング機能が必須。
- チーム体制:高い技術力を持つ専任チームがいる。コストよりもパフォーマンスとスケーラビリティを重視。
- 結論:プロトタイピングレベルの技術では要件を満たせない。大規模運用に耐えうるハイパフォーマンスな専用DBが必須。コストをかけてでも最高の性能を追求する。
- 具体的な選択肢:
- Pinecone:マネージドサービスの中では、大規模・高性能ユースケースでの実績が最も豊富。運用負荷を下げつつ最高のパフォーマンスを求めるなら第一候補。
- Milvus (Self-hosted):自社でインフラを完全にコントロールし、コストを最適化しつつ極限まで性能をチューニングしたい場合に最適。技術力のあるチームがいてこそ活きる選択肢。
- Qdrant:複雑なフィルタリング条件(例:「在庫あり」「セール対象」「評価4.5以上」など)を多用する推薦ロジックの場合、その高速なフィルタリング性能が大きな武器になる。
H2: 導入前に知っておきたい!ベクトルDBのよくある質問(FAQ)
最後に、ベクトルデータベースを検討する際によく寄せられる質問とその回答をまとめました。
Q1: 無料で使えるベクトルDBはありますか?
はい、あります。多くのサービスが無料プランやトライアルを提供しています。
- オープンソース (OSS):
pgvector,Milvus,Chromaなどのソフトウェア自体は無料で、自分たちのサーバーで動かすことができます(サーバー代はかかります)。 - マネージド/PaaS:
Pinecone,Qdrant,Supabase (pgvector)などは、一定のデータ量やリクエスト数までは無料で利用できるプランを用意しています。プロトタイピングや小規模なアプリケーションであれば、無料枠で十分に開発・運用が可能です。
Q2: 最近よく聞くpgvectorの性能って、本番環境で本当に十分なんですか?
結論から言うと、多くのユースケースで「十分に高性能」です。かつては専用DBに劣ると言われていましたが、HNSWインデックスの実装や、Timescale社によるpgvectorscaleのような拡張機能の登場により、パフォーマンスは劇的に向上しました。数百万〜数千万ベクトル規模であれば、適切なチューニングを行うことで、多くの本番アプリケーションの要件を満たすことが可能です。データの一元管理という大きなメリットを考慮すると、非常に有力な選択肢と言えます。
Q3: ベクトルDBのセキュリティで特に気をつけることは何ですか?
通常のデータベースと同様のセキュリティ対策に加え、AIモデルとデータのやり取りに注意が必要です。
- APIキーの管理:OpenAIなどの外部APIを利用する場合、APIキーの漏洩は深刻な問題につながります。厳重に管理してください。
- データのマスキング:個人情報などの機密情報をベクトル化する際は、事前にマスキング処理を行うなどの配慮が求められます。
- AI倫理:AIが生成する内容が倫理的に問題ないか、差別的な表現を含まないかなどを考慮することも重要です。総務省の「AI開発ガイドライン」などは、開発者が配慮すべき点を網羅しており、一読をお勧めします。 (出典:総務省「AI開発ガイドライン」)
Q4: 日本語の文章を扱う上で、特別な注意点はありますか?
はい、埋め込みモデル(Embedding Model)の選択が非常に重要です。ベクトルデータベース自体は言語を区別しませんが、日本語の「意味」を正しくベクトルに変換できるかは、使用するAIモデルの性能にかかっています。日本語に特化して学習された高性能なモデル(例:intfloat/multilingual-e5-largeなど、Hugging Faceで公開されているモデル)を選択することが、検索精度を大きく左右します。
Q5: 導入後の運用で、意外と大変なことは何ですか?
「インデックスの再構築」と「コスト監視」です。
- インデックスの再構築:データを大量に追加・更新した場合、検索性能を維持するためにインデックスの再構築やチューニングが必要になることがあります。特にセルフホストの場合は、この運用を自動化する仕組み作りが求められます。
- コスト監視:マネージドの従量課金サービスでは、意図しない大量のリクエストやデータ登録で、コストが予期せず跳ね上がることがあります。定期的なコスト監視と、必要に応じたアラート設定が重要です。
Q6: LangChainやLlamaIndexとの連携はどのDBでも簡単ですか?
はい、主要なベクトルDBのほとんどは、LangChainやLlamaIndexに公式に対応(インテグレーション)しています。これらのフレームワークは、様々なベクトルDBを統一的なインターフェースで扱えるように抽象化してくれます。そのため、開発の初期段階ではChromaで試し、後からPineconeやpgvectorに差し替える、といったことも比較的容易に行えます。これにより、特定のDBに縛られずに開発を進められるメリットがあります。
H2: まとめ:最適なベクトルDB選びは、未来のAI戦略を描く第一歩
本記事では、ベクトルデータベースの基本から、失敗しないための5つの選定ポイント、主要サービス9選の徹底比較、そして具体的なユースケースまで、網羅的に解説してきました。
H3: 本記事のポイントおさらい
- ベクトルDBは、AIに外部の知識を与えるRAG技術の中核を担う、「意味」で検索できるデータベースです。
- 最適なDBは、**「目的」と「チーム体制」**によって決まります。万能な銀の弾丸はありません。
- 選定は**「マネージド(購入)」と「自社構築(構築)」**の2つのアプローチから考えます。スピードを取るか、柔軟性を取るかのトレードオフです。
- pgvectorの台頭により、必ずしも専門DBが必須ではなくなりました。データの一元管理は大きなメリットです。
- セキュリティやコスト管理など、運用面まで見据えた選定が、プロジェクトの成否を分けます。
ここまで読み進めてくださったあなたは、もうベクトルデータベースの選択肢を前にして途方に暮れることはないはずです。それぞれのメリット・デメリットを理解し、ご自身の状況に合わせた判断軸を持つことができたのではないでしょうか。
H3: 次のステップ:まずは小さなPoC(概念実証)から始めよう
最後に、あなたの取るべき次のアクションをご提案します。それは、**「小さな概念実証(PoC)をすぐに始めてみること」**です。
SupabaseやChromaを使えば、数時間から数日で、基本的なRAGアプリケーションのプロトタイプを構築できます。この低コストな実験は、机上で比較検討するだけでは得られない、貴重な実践的知見をもたらしてくれます。
- 実際に手を動かすことで、開発の難易度や必要な工数が肌感覚でわかる。
- 自分たちのデータで試すことで、検索精度のリアルな感触が得られる。
- PoCの結果をもとに、マネージドサービスにかかる費用対効果をより正確に評価できる。
ベクトルデータベースの選定は、単なる技術選択ではありません。それは、あなたの会社やプロジェクトが、これからAIとどう向き合い、どんな価値を創造していくのかという、未来の戦略を描くための重要な第一歩です。
この記事が、その素晴らしい一歩を踏み出すための、信頼できる地図となることを心から願っています。
📱 関連ショート動画
この記事の内容をショート動画で解説
著者について

原田賢治
代表取締役・AI技術責任者
Mike King理論に基づくレリバンスエンジニアリング専門家。生成AI検索最適化、ChatGPT・Perplexity対応のGEO実装、企業向けAI研修を手がける。 15年以上のAI・システム開発経験を持ち、全国で企業のDX・AI活用、退職代行サービスを支援。