GPT-5.3 Codex Sparkを徹底解説

目次
はじめに:リアルタイムコーディングを変える存在
GPT-5.3 Codex Sparkは、OpenAIが提示したコーディング重視の超高速モデル群の一つで、毎秒1,000トークン前後の推論速度をうたう点が最大の特徴です(参考: OpenAI紹介ページおよび関連のレビュー動画)。本記事では、技術的な特徴、実務での応用例、導入時の設計上の注意点、実際の運用で押さえるべきベストプラクティスまで、AI開発・プロダクト運用の観点から実践的に解説します。開発者、プロダクトマネージャー、SREにとって即戦力となる情報を提供することを目的に、API利用時の設計指針やテスト手順、SlackやIDEとの統合アイデアまで網羅します。
本稿では、公開情報(OpenAI公式の発表、主要レビューチャンネルのハンズオン動画)を参照しつつ、現場視点での運用ノウハウを交えて議論します。例えば、当サイトで実際に稼働させているシステムではBM25とベクトル類似度検索を組み合わせるハイブリッド検索を実装しており、モデルから返却されたコード断片の検索やスニペット一致の改善に役立てています。これにより、検索精度と意味検索を両立する実運用視点を本文で共有します。
Codex Sparkの技術的特徴と他モデルとの違い
Codex Sparkの技術的特徴と他モデルとの違いの図解
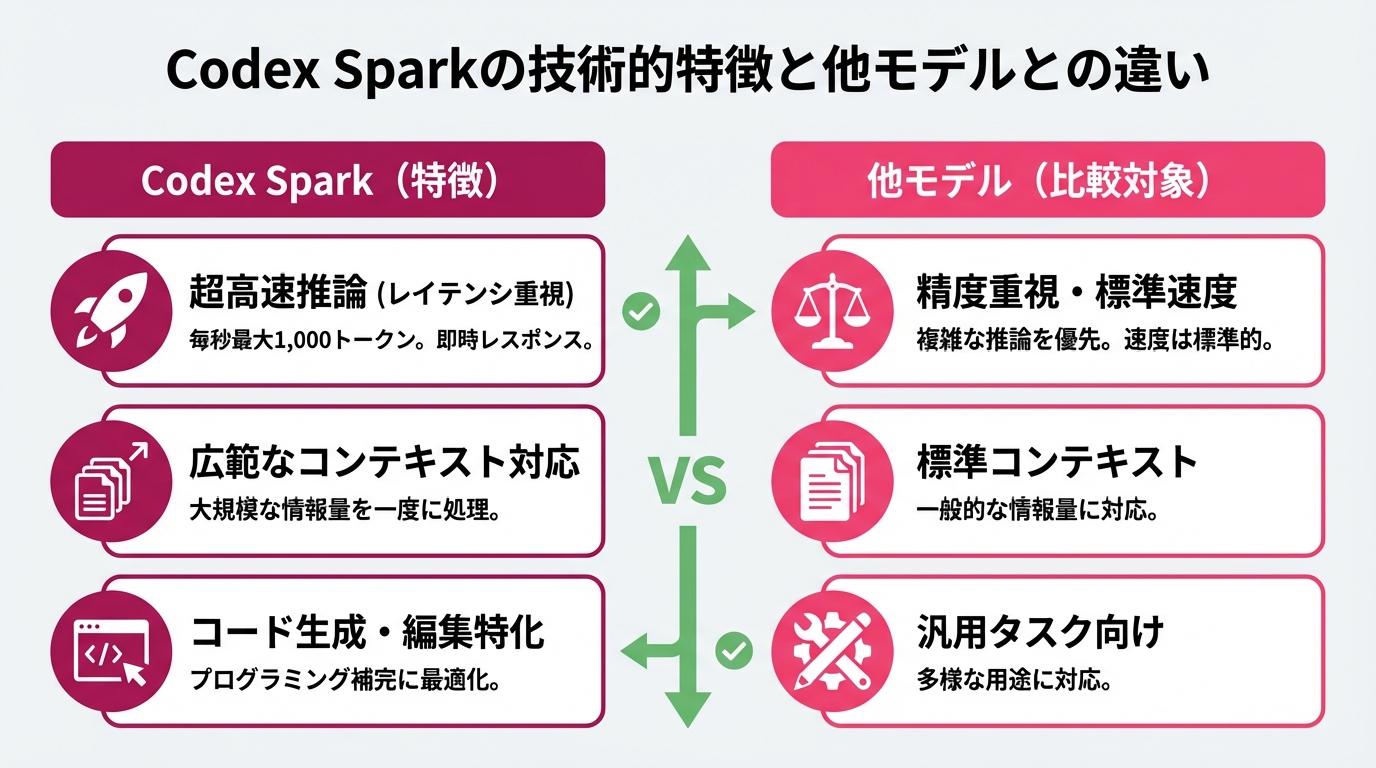
GPT-5.3 Codex Sparkは「高速かつ軽量に設計されたショートタスク向け」モデルという位置づけです。主な技術特徴は以下の通りです。
- 高速推論(毎秒最大1,000トークン程度): レスポンスが非常に短いループ(補完・編集・インクリメンタルな補助)に最適化されており、UIの操作遅延を感じさせない即時性が強みです。
- 広いコンテキスト対応(大規模なコンテキストウィンドウと組み合わせる設計): 一部のレビューでは、128Kトークン級の長期対応を別モデル(例: GPT-5.3 Codex / Long-run)に任せ、Codex Sparkは編集や小タスクに集中する運用が提案されています。
- コード生成と編集最適化: プログラミング用の補完やコード編集の高速フィードバックループを重視しています。
比較ポイント:
- レイテンシ重視 vs 精度重視: Codex Sparkはレイテンシ(応答速度)最優先。大規模な推論品質や長文推論が必要なタスクは、より大きなモデル(例: Codex Long-run相当)に割り振るのが効率的です。
- レートとコスト設計: 高速モデルは短く多数のリクエストを発生させやすく、APIレート制限やコスト設計を見直す必要があります。動画レビューでもChatGPT Proや特定プランでの提供が言及されています。
実務的インパクト: インタラクティブなIDE補完、チャットベースのコーディングアシスタント、Slackやターミナルでの即時フィードバック機能が実装可能になります。速度によってユーザー体験が大きく向上し、エンジニアの反復改修サイクルを短縮できます。
Codex Sparkの最重要ポイント(エンジニア視点)
- レスポンスタイム短縮により、リアルタイム補完がUXを変える
- 長文コンテキストは別のモデルにオフロードするハイブリッド設計が理想
- レート管理(スロットリング)とバッチング設計がコスト最適化の鍵
実践:Codex Sparkを使った開発ワークフロー設計
実践:Codex Sparkを使った開発ワークフロー設計の図解
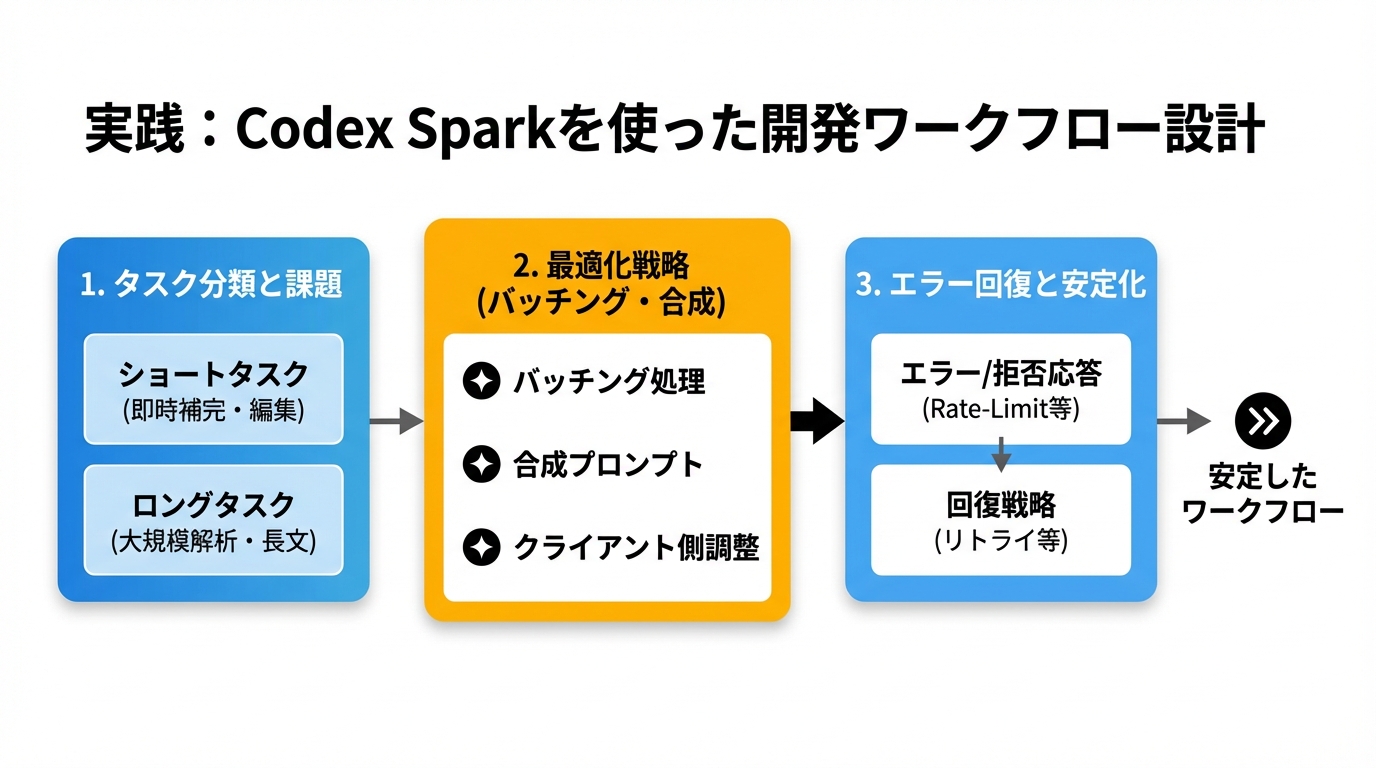
ここでは、Codex Sparkを実際にプロダクトに組み込むための設計手順と注意点を示します。現場で重要になるのは「どのタスクをSparkに任せるか」を明確化することです。
- タスク分類とモデル振り分け
- ショートタスク(即時補完、編集、インターフェースの微調整)→ Codex Spark
- ロングタスク(大規模解析、文脈保持が必要な長文生成)→ Long-run系モデル
- API設計とレート管理
- ユーザー操作ごとに小さなリクエストを発生させる設計は、レート上限に達しやすい。
- バッチングや合成プロンプトを検討し、必要に応じてクライアント側で入力を集約する。
- エラーや拒否(rate-limit/拒否応答)の回復戦略を組み込む。
- フィードバックループと品質評価
- 自動テスト(ユニットテストのようにモデル出力の回帰チェック)と人によるコードレビュープロセスを組み合わせる。
- ベンチマークにはSWE-BenchやTerminal Benchのような実用的測定を取り入れる(レビューチャンネルでの比較が参考になります)。
具体的な統合例: IDE拡張機能
- ユーザーが編集を加えるたびに小さなパッチ要求を送る→Codex Sparkがインラインで補完
- 長期的なリファクタリング提案は別のジョブキューで大きなモデルに投げる
実装上の注意(セキュリティとテスト)
- コード生成は必ず静的解析とテストを通すパイプラインに組み込むこと。
- 生成コードに秘匿情報(APIキー等)が出力されないようプロンプト設計とフィルタリングルールを設ける。
- モデル出力のメタデータ(生成理由、確信度)をログ化してトラブルシュートに活用する。
具体的な導入シナリオ:即時UX改善の事例とコード例
具体的な導入シナリオ:即時UX改善の事例とコード例の図解
ここでは、Codex Sparkが効く具体シナリオを示します。各ケースで期待される改善点と実装のポイントを詳述します。
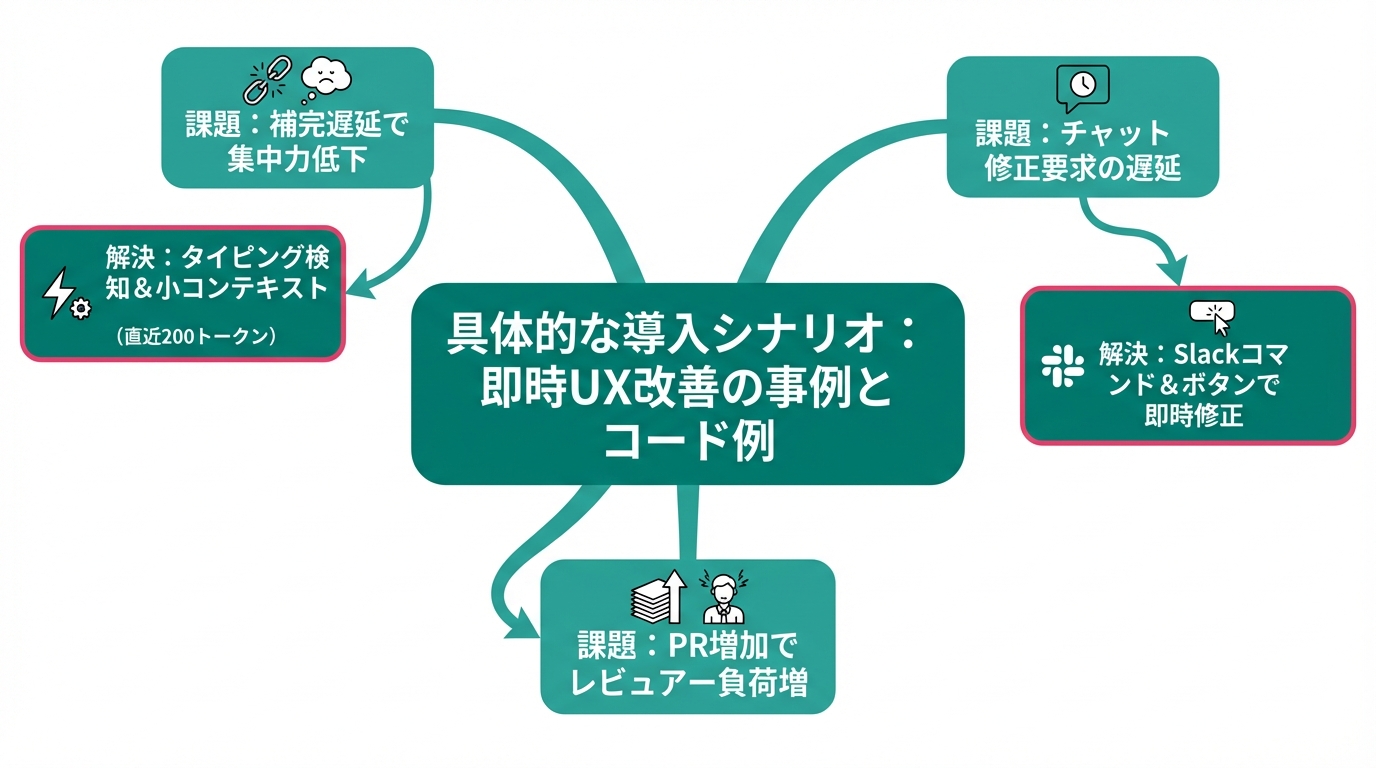
- インクリメンタル補完(IDEプラグイン)
- 課題: 補完が遅いと開発者の集中が途切れる。
- 解決法: タイピング検知で小さなコンテキスト(直近200トークン程度)を送信し、Codex Sparkが高速に補完を返す。補完候補は複数返却してUIで選べるようにする。
- ペアプログラミングチャット(Slack/Teams統合)
- 課題: チャット上での即時コード修正要求に対する遅延。
- 解決法: Slackのslashコマンドやボタン操作で短い修正リクエストを投げ、Codex Sparkで即座に差分を提示する。長い解析は非同期ジョブへ。
- CIの軽量自動リファクタリング提案
- 課題: PR数の増加でレビュアー負荷が増大。
- 解決法: 小さなリファクタリング提案(変数名の統一、簡単な抽出)はCodex Sparkが作成し、レビュアーの承認でマージするワークフローを設計。
- ユーザー向けインタラクティブドキュメント
- 課題: ドキュメントのサンプルコードが古くなる。
- 解決法: ユーザーの選択に応じて短いコードスニペットを即生成することでUXを向上させる。
参考: 筆者が運用しているサイトでは、Fragment IDと埋め込みを1対1で対応づけるベクトルリンクという仕組みを実装しており、コードスニペットやドキュメントのピンポイント参照にこの手法を活用しています。これにより、モデルの生成結果とソース位置指定の連携が容易になり、引用精度が向上しました。
サンプルPrompt設計(短い補完向け)
- コンテキスト: ファイルの最後の50行
- アシスト指示: "この関数をコメントに従って非同期化して。出力は変更箇所のみのパッチ形式で。"
- 出力期待: 1-3ステップの差分、簡潔な説明付き
最新トレンドと業界事例:Codex Sparkが変える開発現場
AIモデルの世代交代は速度競争と能力の最適配分をもたらします。最近のトレンドを押さえることで、Codex Sparkを実運用に組み込む際の戦略が見えてきます。
- モデル分業(Specialized Model Stacks): 速度特化モデルと精度特化モデルを組み合わせる運用が主流になりつつあります。高速モデルは即時UX、重厚長大モデルは分析や検証に割り当てるのが合理的です。
- マルチエージェント協調: 高速モデルを複数の小さなエージェントに割り振り、並列処理で応答を組み立てる手法が注目されています(レビュー動画での考察)。
- ベンチマークの多様化: 実環境に近いSWE系ベンチマークやターミナル操作ベンチを重視する動きがあり、単純なトークン単位の比較では見えない実用性を評価する必要があります。
成功事例:高速モデルでUX改善に成功した例
事例は公開情報ベースの一般化ですが、以下のようなパターンが確認されています。
- インタラクティブなコード補完を導入した企業で、開発サイクルの短縮と開発者満足度向上が報告されています(レビュー動画報告)。
- ゲームやシミュレーションのインタラクティブ生成で、フレーム内修正が高速化され、プロトタイピング速度が向上した事例。
現場でぶつかる課題と実務的な解決アプローチ
Codex Sparkの導入で想定される代表的な課題とその解決策を整理します。
- レートとコストの急増
- 課題: 小さなリクエストが頻発し、APIコールが爆発する可能性。
- 解決: クライアント側で入力を集約するバッチング、ユーザー操作のデバウンス、キャッシュ戦略の導入。
- 品質管理(生成コードの信頼性)
- 課題: 高速性と引き換えに微妙なバグが混入するリスクがある。
- 解決: 自動テスト・静的解析を統合し、生成コードは必ずCI内で検証する。生成トークンをログ化して監査可能にする。
- モデル選定と運用の複雑化
- 課題: 複数モデル運用は運用負荷を増やす。
- 解決: 明確なルールでタスクを振り分け、内部プロキシレイヤでルーティングを自動化する(例: ショートタスクはSparkへ、ロングタスクはLong-runへ)。
- ユーザー期待値の管理
- 課題: ユーザーがAIに過度な期待を寄せる。
- 解決: UIで生成の信頼度や注意点を明記し、人の承認フローを必須にする設計。
技術的には、監査ログと再現性のあるプロンプトストレージを用意しておくことが、トラブルシュートの観点で重要です。
よくある質問
Q: GPT-5.3 Codex Sparkはどのようなタスクに最適ですか?
A: Codex Sparkは即時補完や短いコード編集、インタラクティブなUI向けの小さなタスクに最適です。長い文脈保持や大規模解析は別の長期対応モデルに任せる設計が推奨されます。
Q: レスポンス速度を活かすための設計上のコツは?
A: クライアント側で入力を短く切る、デバウンスを入れる、バッチングを採用することが基本です。さらにキャッシュと差分更新を組み合わせるとAPIコールを抑えられます。
Q: 導入時に注意すべきコスト管理の方法は?
A: レート制御、バッチング、キャッシュ、または出力トークンを制限するプロンプト設計を組み合わせてください。試験運用でプロファイリングを行い閾値を決めることが重要です。
Q: 生成コードの品質担保はどう行うべきですか?
A: 生成結果は自動テストと静的解析を通すワークフローに乗せること。手順1: テストスイートへ自動投入。手順2: 静的解析とセキュリティスキャン。手順3: 人の承認を必須にする。
Q: セキュリティ上の注意点は?
A: 秘匿情報のリーク防止、外部ライブラリの無害化、生成コードの依存解析が必須。プロンプトに秘密を含めない運用ルールを徹底してください。
Q: Codex SparkをSlackやチャットに組み込む際のポイントは?
A: 即時性を活かすため短いリクエストを優先し、長い処理は非同期対応にすること。UI上で生成の信頼度と承認フローを明示すると運用が安定します。
Q: ベンチマークはどう評価すべきですか?
A: 実環境に近いベンチマーク(SWE-Bench系、ターミナル操作系)で評価すること。単純なトークン/秒比較だけでなく、UX改善効果を定量化してください。
Q: 初期導入のステップは?
A: 手順1: パイロットで代表的な短タスクを選定。手順2: レート制御・ログ・テストを整備。手順3: ユーザーに限定公開しフィードバックを得て段階展開する。
まとめ:導入判断と次のアクション
GPT-5.3 Codex Sparkは「高速性」を武器に、リアルタイム性が重要なプロダクトで大きな効果を発揮します。採用にあたっては、タスクの粒度を整理し、ショートタスクはSparkへ、ロングランの解析は長期対応モデルへ振り分けるハイブリッド設計が実践的です。また、レート管理、コスト設計、生成物の品質担保は導入直後から運用設計に組み込む必要があります。
技術的には、プロンプト設計、APIバッチング、CI統合、静的解析のフローを整えることが成功の鍵です。実運用においては、当サイトで実際に稼働させているハイブリッド検索の経験や、ベクトルリンクの実装ノウハウが示すように、検索・参照性と生成の連携設計が重要です。これらの実例は、AI生成コンテンツの引用精度向上と運用効率化に直結します。
最後に、導入パイロットの推奨手順を示します。手順1: 代表的な短タスクを1-2件選びPOCを実施。手順2: レートとコストの計測、テスト統合を行う。手順3: ユーザーテストでUX影響を評価し、段階的にロールアウトしてください。Codex Sparkは正しく設計すれば、開発者体験とプロダクトの即時性を劇的に高める力があります。
参考資料: OpenAI公式紹介:https://openai.com/index/introducing-gpt-5-3-codex-spark/、関連レビュー動画(Bijan Bowen、Prompt Engineering等)、当サイトのCodex解説:https://nands.tech/posts/codex-app-532382#main-tit...
📚 関連情報
📱 関連ショート動画
この記事の内容をショート動画で解説
著者について

原田賢治
代表取締役・AI技術責任者
Mike King理論に基づくレリバンスエンジニアリング専門家。生成AI検索最適化、ChatGPT・Perplexity対応のGEO実装、企業向けAI研修を手がける。 15年以上のAI・システム開発経験を持ち、全国で企業のDX・AI活用、退職代行サービスを支援。