Claude Sonnet 4.6 実務導入ガイド:長文・安全・開発導線で「PoC止まり」を終わらせる

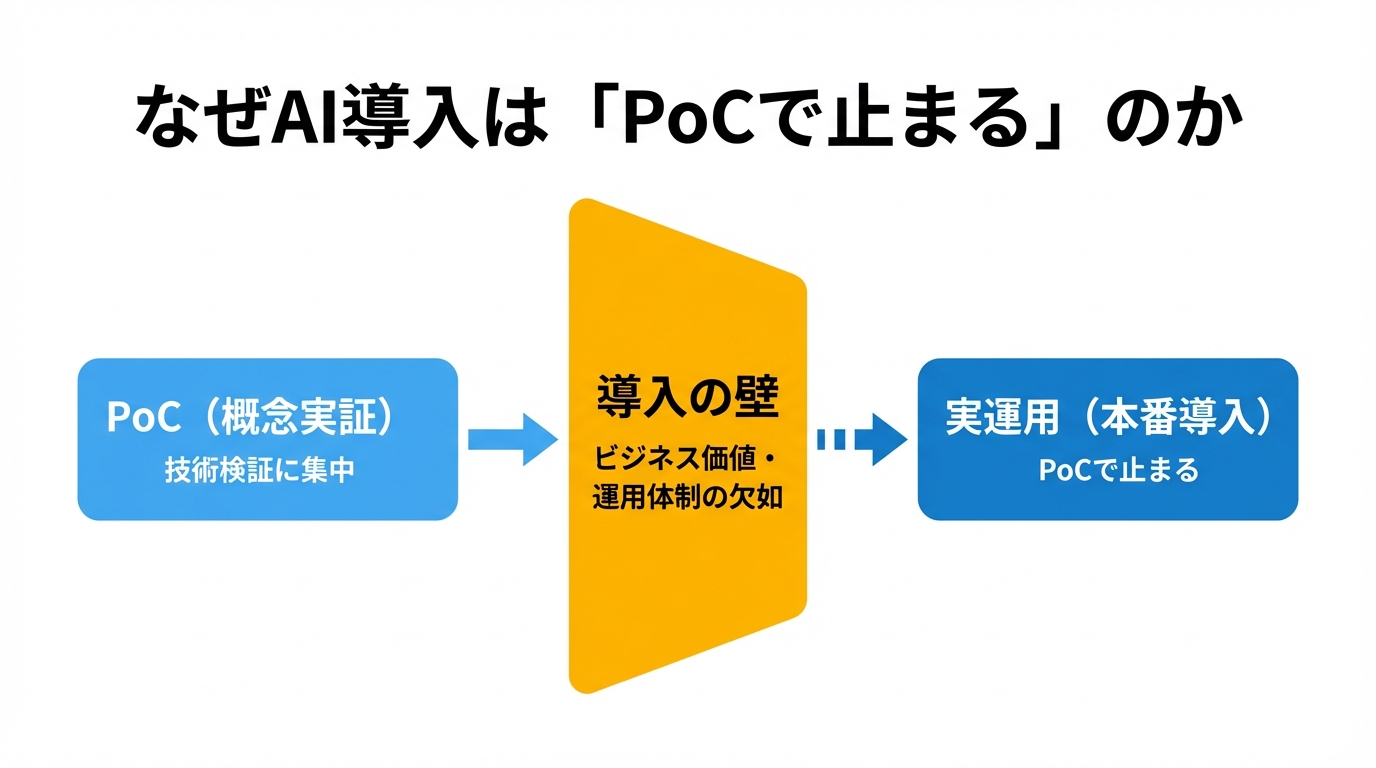
なぜAI導入は「PoCで止まる」のか
なぜAI導入は「PoCで止まる」のかの図解
AIは賢くなりました。それでも現場で詰まる理由はだいたい同じです。
- どの資料を読ませるかが毎回バラバラ(入力が不安定)
- 出力の合格ラインが決まっていない(評価がない)
- 誰が責任を持つか不明(承認とログがない)
つまり、問題はモデルより“回る仕組み”です。
Sonnet 4.6で増えた「現場で使える選択肢」だけ押さえる
1) 一度に読める量が大きい(200K、条件付きで1M)
ポイント:“入るか”より“運用できるか”。まず200K運用で勝つ方が成功率が上がります。
2) 出力が長く書ける(最大64K)
Sonnet 4.6は最大64K出力に対応しています。長い要約、仕様の洗い出し、手順書の生成が途中で途切れにくくなります。 (Claude)
3) 「考える深さ」を雑にコントロールできる(adaptive + effort)
- Sonnet 4.6はadaptive thinking対応。古い方式(
budget_tokens)は将来削除予定です。 (Claude) - “どれだけ深く考えるか”は
effortでざっくり調整できます(low/medium/high)。 (Claude)
ポイント:実務では「いつも最強設定」ではなく、“いつ深く考えさせるか”を決める方がコストと品質が安定します。
4) 検索・取得・コード実行などのツールが「正式版」扱いになった
Web取得(fetch)やコード実行など、業務で使いがちなツールが一般提供(GA)として整理されています。 (Claude)
まず決める:Sonnet 4.6を入れて「どの仕事を勝つか」
導入がうまくいくのは、最初の勝ち場所を間違えない時です。
- 長文を読む仕事:規約・契約・議事録・設計書・監査資料
- 条件分岐が多い仕事:受付→振り分け→テンプレ選択→確認→記録
- 開発導線に乗せられる仕事:差分・レビュー・テストができる成果物(PR、仕様、手順書)
Sonnet 4.6は、各種プラン/Claude Code/API など広く提供され、無料枠もSonnet 4.6が既定になっています(=社内展開の障壁が下がる)。 (Anthropic)
PoC止まりを終わらせる「手戻りが少ない順番」
ステップ1:タスクを3つに分けて、最初の勝ち筋を選ぶ
- 読む(要約/比較/抜け漏れ):正誤が取りやすく、副作用が小さい
- 書く(文章整形/テンプレ化):成果が見えやすいが、誇張リスクに注意
- 動かす(自動化/ツール実行):効果が大きいが、権限設計が必須
最初は基本的に「読む」から入るのが堅い。〔原理〕
ステップ2:入力を固定する(プロンプトより効く)
最低限、毎回これを揃えます。
- 目的:何を決めたいか(例:リスクを洗い出す、合意点をまとめる)
- 禁止:言い切り禁止、根拠がない内容は禁止、など
- 材料:対象文書(そのまま貼る or 参照先を決める)
- 出力形:箇条書き/表/JSON(固定)
ステップ3:安全を「運用で止める」
モデルに期待しすぎず、仕組みで事故を止めます。
- 禁止事項(個人情報・未公開情報・誇大表現など)
- 承認ポイント(どこで人がOKするか)
- ログ(誰が・何を入力し・何が返り・何を実行したか)
必要なら推論をUSに限定する設定もできますが、対象モデルでは価格係数が上がります(例:US-onlyは1.1x)。 (Claude)
ステップ4:評価セット(10件)を作って、改善を回す
「良さそう」で止めないために、最小でもこれだけ作ります。
- 代表タスク10件(入力と期待の形)
- NG例(やってはいけない出力)
- 採点(根拠のある記述か/形式を守ったか/抜け漏れ)
2週間でやる「最小の本番化テスト」
Day 1–2:代表タスク10件を集める(失敗しても被害が小さいもの)Day 3–4:入力テンプレ・出力テンプレを固定Day 5–7:実行→採点→失敗パターンを分類Week 2:改善してもう一周→合否判定
合格ライン例
- “根拠のない言い切り” 0〜1件/10
- 形式違反 2件未満/10
- 修正往復 1回以内/件(8件以上)
すぐ使えるテンプレ(わかりやすい日本語版)
テンプレ1:長文を「5分で判断できる形」にする
あなたは業務の整理役です。次の文書を読み、事実と判断材料を分けてまとめてください。 【このまとめの目的】 - 責任者が5分で「論点・リスク・次の手」を判断できるようにする 【やってはいけないこと】 - 文書に書かれていない内容を“事実”として言い切らない - 根拠がない推測で穴埋めしない 【書き方(固定)】 1) 結論(3行) 2) 重要ポイント(箇条書き) 3) 未決事項(担当/期限があれば書く) 4) リスク(どこが根拠か短く引用) 5) 次にやること(優先度つき) 【文書】 --- ここに貼る ---
テンプレ2:要件定義を「穴あきチェック」する
次の要件から、現場で揉めやすい“穴”を見つけてください(曖昧・未定義・矛盾)。 【チェック観点】 - 用語の定義(同じ言葉の意味が揺れていないか) - 例外時(失敗/タイムアウト/再試行) - 権限(誰が何をできるか) - 記録(後から追えるログがあるか) - 性能(遅いと困る場面はどこか) 【出力(固定)】 - 指摘:… - 根拠:”…“(該当箇所を短く引用) - 影響:… - 直し案:… - 確認したい質問:… 【要件】 --- ここに貼る ---
テンプレ3:根拠つき回答(監査できる形)
次の質問に答えてください。ただし必ず「文書の該当箇所」を短く引用してください。 【ルール】 - 引用できないなら「根拠が見つからない」と書く - 推測で埋めない - 断定ではなく条件つきで述べる 【質問】 ... 【文書】 ... 【出力(固定)】 - 回答: - 根拠(引用): - 根拠が足りない点: - 追加で欲しい情報:
実装の最小設計:LLMを“業務部品”にするラッパー
やるべきことは単純です。アプリ側で吸収します。
- 入力チェック(個人情報が入っていないか、サイズ上限)
- JSON検証(壊れたら再試行)
- ログ(入力/出力/モデル/設定/担当/stop_reason)
- 再試行(回数制限、タイムアウト)
- 承認(ツール実行や外部送信の前に人がOK)
ツール(fetch/コード実行など)が正式提供になっている分、“どこまで自動でやっていいか”の線引きが重要になります。 (Claude)
コード例(最小):adaptive + effortで呼ぶ
TypeScript(公式SDKの形に寄せた最小例)
import Anthropic from "@anthropic-ai/sdk"; const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY! }); export async function summarize(doc: string) { const prompt = ` あなたは業務の整理役です。事実と判断材料を分けてまとめてください。 【禁止】 - 文書にない内容を言い切らない - 推測で穴埋めしない 【出力】JSONのみ { "conclusion": "string", "points": ["string"], "risks": [{"risk":"string","quote":"string"}], "next_actions": [{"action":"string","priority":"P0|P1|P2"}] } 【文書】 ${doc} `.trim(); const res = await client.messages.create({ model: "claude-sonnet-4-6", max_tokens: 6000, thinking: { type: "adaptive" }, output_config: { effort: "medium" }, messages: [{ role: "user", content: prompt }], }); const text = res.content[0].type === "text" ? res.content[0].text : ""; return JSON.parse(text); }
TypeScript SDKのmessages.createで呼び出せます。 (Claude)
Python(ドキュメント例と同形)
import anthropic, json client = anthropic.Anthropic() def ask(doc: str): res = client.messages.create( model="claude-sonnet-4-6", max_tokens=6000, thinking={"type": "adaptive"}, output_config={"effort": "medium"}, messages=[{"role": "user", "content": doc}], ) return res.content[0].text
thinking: adaptiveとoutput_config.effortの組み合わせが推奨です。 (Claude)
コストで失敗しないコツ(ここだけ守る)
まとめ:次にやること
- 代表タスク10件で評価セットを作る
- 入力(目的/禁止/材料/出力形)を固定する
- ログ+承認ポイントを先に決める
- まず200K運用で勝ち、1Mは例外案件に限定する (Claude)
必要なら、あなたの事業(退職/給付/人材紹介)で「最初に勝つべき10タスク」をこちらで仮置きして、2週間の評価セット(入力テンプレ+採点表)まで一気に作るところまで落とします。
📱 関連ショート動画
この記事の内容をショート動画で解説
著者について

原田賢治
代表取締役・AI技術責任者
Mike King理論に基づくレリバンスエンジニアリング専門家。生成AI検索最適化、ChatGPT・Perplexity対応のGEO実装、企業向けAI研修を手がける。 15年以上のAI・システム開発経験を持ち、全国で企業のDX・AI活用、退職代行サービスを支援。