2026年のAI最新動向を、ビジネス成果につなげる方法

目次
「ツール選定」ではなく「AIが理解して働ける構造」で導入を設計する
AIの話題は毎週のように更新されます。新モデル、新機能、新しいエージェント基盤。情報だけ見れば、いまは「何でもできそう」に見える時代です。 しかし、現場の悩みはむしろ逆です。
- 結局、どれを採用すべきか決めきれない
- PoC は動いたのに、本番で止まる
- 研修はしたのに、成果が測れない
- 結果として、導入コストだけが先に立つ
このギャップは、技術が足りないからではありません。導入の設計単位が間違っているからです。
AIアーキテクトとして私が重視しているのは、AIを“使う”ことそのものではなく、AIが理解して働ける構造を先に設計することです。そこが固まると、ツール選定、データ整備、学習計画、ガバナンス、ROI が一本の線でつながります。
結論から言うと、2025〜2026年のAI活用をビジネス成果につなげる鍵は、次の3つです。
- 「技術トレンド」ではなく「learning outcomes(学習成果)」で導入を設計する
- 生成AI・マルチモーダル・エージェントを“業務フロー単位”で組み込み、運用可能にする
- 成果指標を、品質・速度・再現性・監査可能性の4軸で測る
この3点を押さえると、AIの最新動向は「追いかける情報」ではなく、「意思決定に使う材料」に変わります。
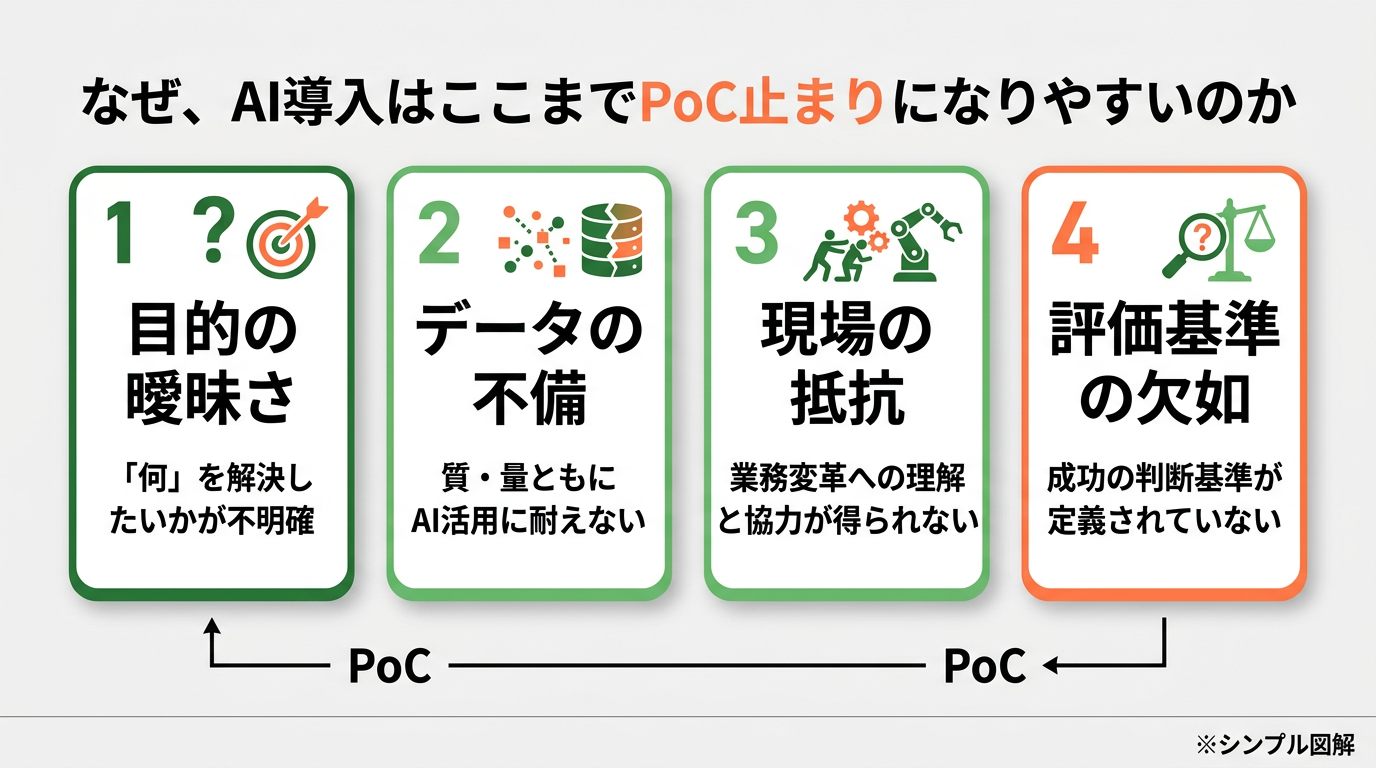
なぜ、AI導入はここまでPoC止まりになりやすいのか
なぜ、AI導入はここまでPoC止まりになりやすいのかの図解
いま、多くの企業はすでにAIを使っています。McKinsey の 2025年調査では、78% の企業が少なくとも1つの業務機能で AI を利用しており、71% が少なくとも1つの業務機能で生成AIを定常利用していると回答しています。つまり、AIはもう“試すかどうか”の段階ではありません。実際にはかなり広く使われています。 (McKinsey & Company)
それでも、成果が見えにくい企業が多いのはなぜか。 同じ McKinsey 調査では、生成AIの導入・拡張に関する12の実践項目の大半を実行できている企業は3分の1未満で、明確な KPI を追跡している企業は5社に1社未満でした。さらに、企業全体の EBIT に目に見える影響が出ていないと答えた企業が 80% 超にのぼります。つまり、問題はモデル性能よりも、導入・拡張・運用の設計不足です。
ここから分かるのは、AI導入のボトルネックが「精度そのもの」ではなく、業務への埋め込み方に移っているということです。 PoC が止まる組織は、だいたい次の順で失敗します。
- ツールを先に選ぶ
- 現場の作業を分解しない
- 評価指標を置かない
- 権限・ログ・レビューの設計を後回しにする
- その結果、「使っているのに価値が説明できない」状態になる
この構図を変えるには、AIをプロダクトとして導入するのではなく、業務の一部として運用設計する必要があります。
2025〜2026年の最新動向は、何を意味しているのか
AIの最新動向を単に列挙しても、現場では役に立ちません。重要なのは、「その変化が、どの意思決定を変えるか」です。 いま押さえるべき変化は、実務上は次の4つです。
1. AIは確実に高性能化し、同時に安くなっている
Stanford HAI の 2025 AI Index では、2024年時点で AI の業務利用が加速し、企業の AI 利用率は 55% から 78% に上昇しました。加えて、GPT-3.5 水準の性能を持つシステムの推論コストは 2022年11月から2024年10月にかけて 280分の1超まで低下し、ハードウェアコストは年率 30% 低下、エネルギー効率は年率 40% 改善しています。つまり、AI は「高性能になっている」だけでなく、「使える価格帯に落ちてきている」のです。 (Stanford HAI)
ここで重要なのは、性能向上そのものが競争優位ではなくなるということです。 モデルが良くなり、推論コストが下がるほど、差はモデル名ではなく、どの業務データを、どのフローで、どのルールのもとに使うかに移ります。 つまり、価値の源泉は「最強モデル」ではなく、業務構造の設計力に寄っていきます。
2. 生成AIの中心は“単発生成”から“業務フロー”へ移っている
Gartner は 2025年の Hype Cycle で、AI agents と AI-ready data を最も進展の速い技術として挙げ、同時にmultimodal AIとAI trust, risk and security management(TRiSM)を重要論点に位置づけました。ポイントは、関心の中心が「生成AIそのもの」から、それを業務で持続可能に回すための土台へ移っていることです。 (ガートナー)
ただし、ここで冷や水も浴びせておくべきです。 同じ Gartner は 2025年6月、2027年末までに agentic AI プロジェクトの 40% 超が中止される見通しを示しました。理由は、コストの増大、曖昧なビジネス価値、不十分なリスク管理です。つまり、エージェントは期待値が高い一方で、雑に入れると高確率で失敗する領域でもあります。 (ガートナー)
要するに、2025〜2026年のトレンドは「エージェントが熱い」という話ではありません。 正確には、AIを複数ステップの業務に組み込む時代に入り、その成否を分けるのがデータ整備とガバナンスになった、ということです。
3. マルチモーダルは“派手な機能”ではなく“入力の壁を壊す技術”になった
マルチモーダルというと、画像生成や動画生成の派手さに目が行きがちです。 しかし、現場で効くのはそこではありません。効くのは、テキストで整理されていない情報を、AIが扱える入力に変えられることです。
McKinsey の調査でも、生成AIの出力はテキストだけにとどまらず、画像生成を使う企業が3分の1超、コード生成を使う企業が4分の1超に広がっています。これは、業務で扱う情報形式がすでに多様化していることを示しています。
ここでの本質は、 **「AIに何を作らせるか」より、「現場のどの入力をAIが扱えるようにするか」**です。
- 会議音声を議事録に変える
- 画像や紙帳票を分類可能なデータに変える
- 動画や画面キャプチャを手順書の素材に変える
マルチモーダルは、アウトプットを華やかにする技術というより、業務入力の非構造性を崩す技術として見る方が実務に刺さります。
4. AI投資は、モデル利用料より“運用コスト”が効いてくる
AIコストを API 単価だけで見る時代は終わりつつあります。 IEA の 2025年レポートでは、世界のデータセンター電力消費は 2030年までに約 945TWh へ倍増し、世界全体の電力消費の 3%弱に達すると見込まれています。2024〜2030年のデータセンター電力消費は年率約 15% で伸び、AI普及で増える accelerated servers が、その増加の大きな要因になるとされています。 (IEA)
この意味は大きいです。 AI の経済性は、単なる「1回いくらの推論費用」ではなく、
- どのモデルをどの頻度で使うか
- リアルタイム処理とバッチ処理をどう分けるか
- 監査や再生成のためにどれだけログを残すか
- 高価なモデルをどの工程だけに使うか
といったアーキテクチャ設計に依存する比率が上がる、ということです。
「Understanding AI and learning outcomes」をビジネスに翻訳する
ここからが実務です。 AI 活用が失敗する組織には、共通点があります。 それは、AI を理解することと、業務で成果を出すことがつながっていないことです。
研修はした。ツールも入れた。 でも、現場はこうなりがちです。
- 何を根拠に出力を採用してよいか分からない
- 人によって使い方が違い、品質が安定しない
- 誰が責任を持つのか曖昧
- 結果として、業務フローに組み込めない
だから、私は learning outcomes を次の4つに翻訳して設計します。
1. 人が「説明できるようになる」
たとえば、
- この業務で AI を使ってよい範囲
- 根拠が必要な場面
- 個人情報や機密を扱うときの禁止事項 を説明できる状態です。
2. 人が「再現できるようになる」
同じような入力に対して、担当者が変わっても一定品質を出せる状態です。 これは“プロンプトのうまさ”ではなく、手順・テンプレ・レビュー観点の共有で実現します。
3. 組織が「運用できるようになる」
権限、ログ、監査、例外処理、人間への引き継ぎ条件が決まっている状態です。 ここがないと、PoC は動いても本番では止まります。
4. 組織が「改善できるようになる」
KPI があり、出力の品質差分が見え、プロンプト・ルール・データを更新できる状態です。 改善不能な AI 導入は、時間差で必ず劣化します。
この4つが揃って初めて、AI導入は「研修」や「検証」ではなく、業務能力の獲得になります。
生成AI・マルチモーダル・エージェントを、どう業務フローに組み込むか
高品質な導入は、ツール比較から始めません。業務を“タスクの束”に分解するところから始めます。
たとえば、問い合わせ対応なら、実際には次の工程があります。
- 問い合わせを受ける
- 内容を分類する
- 関連する社内ナレッジを探す
- 返信案を作る
- 人がレビューする
- 送信し、履歴を残す
ここで重要なのは、AIを一気に全部へ入れないことです。 まず切り出すべきは、判断コストが高いが、責任移転はしない工程です。
- 分類
- 要約
- 下書き
- ナレッジ検索
- FAQ 候補生成
この領域は、AI の効果が出やすく、かつ人間の最終判断を残しやすい。 逆に最初から送信・登録・承認まで自動化すると、例外処理と監査で崩れやすくなります。
エージェント導入も同じです。 エージェントの本当の価値は「賢く会話すること」ではなく、連続作業の束をほどくことにあります。
- 情報収集 → 要約 → 下書き
- バグ報告 → 再現手順整理 → 修正案
- 議事録化 → タスク抽出 → チケット登録
このように、複数ステップにまたがる手戻りを減らせるなら、エージェント化の意味があります。 単発の文章生成で足りる業務にエージェントを持ち込むと、たいてい複雑さだけが増えます。
成果指標は「品質・速度・再現性・監査可能性」の4軸で置く
AI導入が曖昧に終わる最大の理由は、成果指標が雑だからです。 「工数削減できそう」「便利そう」では、改善も予算説明もできません。
実務では、少なくとも次の4軸を置くべきです。
品質
- 誤答率
- 修正率
- レビュー差し戻し率
- 根拠一致率
速度
- 1件あたり処理時間
- リードタイム
- 初回応答までの時間
再現性
- 担当者が変わっても同品質を出せるか
- 入力テンプレの有無
- 出力形式の揺れの大きさ
監査可能性
- どのデータを参照したか
- どのモデルを使ったか
- どのルールで処理したか
- 誰が最終承認したか
McKinsey の調査で、KPI をきちんと追っている企業が少ないこと、そしてそれが価値創出の差になっていることは示唆的です。AI 導入の差は、モデル差よりも、測っているかどうかでつきます。
実務導入の5ステップ
ここからは、私ならどう設計するかを、最小構成で示します。
ステップ1:業務を「入力・処理・出力」に分解する
まず、部署や業務を抽象語で捉えないことです。 「営業支援」「CS効率化」では粗すぎます。 最低でも次の粒度に落とします。
- 入力:メール、PDF、画像、音声、表
- 処理:抽出、分類、要約、生成、照合
- 出力:文章、表、チケット、メール、登録データ
これをやると、 生成AIで足りるのか、マルチモーダルが必要か、RAG が要るか、エージェント化すべきかが見えます。
ステップ2:learning outcomes を3行で定義する
たとえば CS 部門なら、
- FAQ 候補を生成し、上長レビューで公開できる
- 返信下書きを品質基準内で作成できる
- エスカレーション条件を判断できる
これくらい具体化します。 学習成果がこの粒度で定義されていない研修は、ほぼ確実に“受けただけ”で終わります。
ステップ3:評価指標を先に置く
AI は入れてから測るのではなく、測る前提で入れるべきです。 最初の評価セットは小さくて構いません。 20件、50件、100件でもよいので、レビュー可能なセットを作ります。
ステップ4:小さくエージェント化する
最初は「提案」までに留めます。
- 要約する
- 下書きを作る
- 候補を出す
- チケット案を作る
ここまでは AI。 送信、登録、承認は人間。 この切り分けだけで事故率はかなり下がります。
ステップ5:運用の型を資産化する
最終的に残すべきなのは、モデル名ではありません。 残すべきなのは、
- プロンプトテンプレ
- 入力テンプレ
- チェックリスト
- 根拠データの参照ルール
- 例外時の引き継ぎ条件
です。 ここが資産です。 モデルは入れ替わりますが、運用の型は残ります。
コード例:社内ナレッジを検索して「根拠つき生成」を行う最小構成
以下は、RAG の骨格を理解するための最小例です。 本番では埋め込みモデル、ベクトルDB、認証、ログ、PIIマスキングなどを差し替えてください。 ポイントは、先に検索して根拠を集め、その断片だけを使って回答を作ることです。
from dataclasses import dataclass from typing import List, Dict import math import time @dataclass class Chunk: id: str text: str embedding: List[float] source: str class VectorStore: def __init__(self): self.chunks: List[Chunk] = [] def add(self, chunk: Chunk): self.chunks.append(chunk) def _cosine(self, a: List[float], b: List[float]) -> float: dot = sum(x * y for x, y in zip(a, b)) na = math.sqrt(sum(x * x for x in a)) nb = math.sqrt(sum(y * y for y in b)) return dot / (na * nb + 1e-9) def search(self, query_embedding: List[float], top_k: int = 3) -> List[Chunk]: scored = [(self._cosine(query_embedding, c.embedding), c) for c in self.chunks] scored.sort(key=lambda x: x[0], reverse=True) return [c for _, c in scored[:top_k]] def embed(text: str) -> List[float]: """ ダミー実装。 実運用では OpenAI / Gemini / Voyage / bge / e5 などの埋め込みモデルに置き換える。 """ tokens = text.lower().split() vec = [0.0] * 16 for i, token in enumerate(tokens[:64]): vec[i % 16] += (sum(ord(ch) for ch in token) % 97) / 100.0 return vec def build_prompt(question: str, evidence_blocks: List[Chunk]) -> str: evidence_text = "\n\n".join( [f"[{c.id}] ({c.source})\n{c.text}" for c in evidence_blocks] ) return f""" あなたは社内アシスタントです。 回答は必ず以下の根拠だけを使ってください。 根拠が足りない場合は「不明」と答えてください。 # 質問 {question} # 根拠 {evidence_text} # 出力ルール - まず結論を1文 - 次に根拠を箇条書き - 推測が入る場合は「推測」と明記 """ def generate_answer(prompt: str) -> str: """ ダミー実装。 実運用では LLM API を呼び出し、temperature を低めに固定する。 """ return f"---PROMPT START---\n{prompt[:1200]}\n---PROMPT END---" def log_event(event: Dict): print(f"[LOG] {event}") # --- インデックス作成 --- store = VectorStore() documents = [ { "id": "policy-001", "source": "社内規程", "text": "個人情報を含む原文を外部AIへそのまま入力してはいけない。必要な場合は匿名化・要約・マスキングを行うこと。" }, { "id": "manual-014", "source": "CS手順書", "text": "問い合わせ返信は、分類→テンプレ選択→必要に応じて上長確認→送信の順で行う。個人情報が含まれる場合は上長確認を必須とする。" }, { "id": "faq-007", "source": "FAQ", "text": "AIは返信文の下書き作成まで利用可能。ただし送信判断は担当者が行い、送信前に内容確認を行う。" } ] for doc in documents: store.add( Chunk( id=doc["id"], source=doc["source"], text=doc["text"], embedding=embed(doc["text"]) ) ) # --- 問い合わせ処理 --- question = "顧客名が入ったメール本文をそのままAIに渡して返信案を作ってよいですか?" start = time.time() retrieved = store.search(embed(question), top_k=3) prompt = build_prompt(question, retrieved) answer = generate_answer(prompt) log_event({ "question": question, "retrieved_ids": [c.id for c in retrieved], "elapsed_ms": int((time.time() - start) * 1000), "review_required": True }) print(answer)
この最小構成でも、設計の本質は見えます。AIに直接“答えさせる”のではなく、先に根拠を取りにいき、その根拠の範囲内で答えさせる。 そして、何を参照したかをログに残す。 この2点だけで、現場運用のしやすさは大きく変わります。
PoC 止まりを防ぐために、最初から潰しておくべき失敗パターン
最後に、現場でよく見る失敗パターンを整理しておきます。
1. 「精度が高いモデルを選べば勝てる」と考える
違います。 いまは性能差そのものより、業務データ・フロー・ルール設計の差の方が大きくなっています。 モデルの進化とコスト低下が進むほど、この傾向は強まります。 (Stanford HAI)
2. 研修を“プロンプト講座”で終わらせる
現場で必要なのは、書き方のテクニックよりも、
- 何を入力してよいか
- どこまで自動化してよいか
- 何を根拠として採用するか
- どこで人間に戻すか
という判断基準です。
3. エージェントを最初から本番実行させる
Gartner が指摘する通り、agentic AI は期待先行で失敗しやすい領域です。 まずは候補生成、下書き、要約、分類など、可逆でレビュー可能な工程から始めるべきです。 (ガートナー)
4. ログを残さない
ログがないと、改善できません。 改善できない AI 導入は、たとえ一時的に動いても、時間差で信用を失います。
まとめ:AI時代に勝つのは「新しいツールを知っている会社」ではない
2025〜2026年のAI最新動向をひと言でまとめるなら、こうです。
AIは、性能の競争から、運用の競争に移った。
- AI 利用はすでに広く進んでいる
- モデルは高性能化し、安くなっている
- マルチモーダルとエージェントは業務フローに入ってきている
- その一方で、PoC 止まりや中止案件も増えている
- 差を分けるのは、AI-ready data、KPI、ガバナンス、権限設計、ログ設計である
この状況で成果を出す企業は、トレンドを追うだけではなく、AI が理解して働ける構造を先に作る企業です。 learning outcomes を定義し、業務をタスクに分解し、品質・速度・再現性・監査可能性で測る。 そして、小さく導入し、型として資産化する。
これが、AIを「便利なツール」で終わらせず、ビジネス成果に変える最短ルートです。
📱 関連ショート動画
この記事の内容をショート動画で解説
著者について

原田賢治
代表取締役・AI技術責任者
Mike King理論に基づくレリバンスエンジニアリング専門家。生成AI検索最適化、ChatGPT・Perplexity対応のGEO実装、企業向けAI研修を手がける。 15年以上のAI・システム開発経験を持ち、全国で企業のDX・AI活用、退職代行サービスを支援。